
Mesterséges intelligencia
Kódbeágyazás: Átfogó útmutató

A kódbeágyazás egy transzformatív módszer a kódrészletek sűrű vektorokként való megjelenítésére egy folytonos térben. Ezek a beágyazások rögzítik a kódrészletek közötti szemantikai és funkcionális kapcsolatokat, és hatékony alkalmazásokat tesznek lehetővé az AI által támogatott programozásban. A természetes nyelvi feldolgozásban (NLP) használt szóbeágyazásokhoz hasonlóan a kódbeágyazások a hasonló kódrészleteket egymáshoz közel helyezik el a vektortérben, lehetővé téve a gépek számára a kód hatékonyabb megértését és kezelését.
Mik azok a kódbeágyazások?
A kódbeágyazások az összetett kódstruktúrákat numerikus vektorokká alakítják, amelyek rögzítik a kód jelentését és funkcióit. A hagyományos módszerekkel ellentétben, amelyek a kódot karaktersorozatként kezelik, a beágyazások rögzítik a kód részei közötti szemantikai kapcsolatokat. Ez kulcsfontosságú a különféle mesterséges intelligencia által vezérelt szoftverfejlesztési feladatokhoz, mint például a kódkeresés, a befejezés, a hibaészlelés és egyebek.
Vegyük például ezt a két Python-függvényt:
def add_numbers(a, b):
return a + b
def sum_two_values(x, y):
result = x + y
return result
Noha ezek a funkciók szintaktikailag eltérően néznek ki, ugyanazt a műveletet hajtják végre. Egy jó kódbeágyazás ezt a két függvényt hasonló vektorokkal reprezentálná, megragadva funkcionális hasonlóságukat a szöveges különbségek ellenére.

Vektor beágyazás
Hogyan jönnek létre a kódbeágyazások?
Különféle technikák léteznek a kódbeágyazások létrehozására. Az egyik elterjedt megközelítés a neurális hálózatok használata, hogy megtanulják ezeket a reprezentációkat egy nagy kódadatkészletből. A hálózat elemzi a kódszerkezetet, beleértve a tokeneket (kulcsszavakat, azonosítókat), a szintaxist (a kód felépítését), és esetleg megjegyzéseket, hogy megtanulja a különböző kódrészletek közötti kapcsolatokat.
Bontsuk fel a folyamatot:
- A kód sorozatként: Először is, a kódrészleteket tokenek (változók, kulcsszavak, operátorok) sorozataiként kezeljük.
- Neurális hálózatok képzése: Egy neurális hálózat feldolgozza ezeket a sorozatokat, és megtanulja leképezni őket rögzített méretű vektoros reprezentációkra. A hálózat olyan tényezőket vesz figyelembe, mint a szintaxis, a szemantika és a kódelemek közötti kapcsolatok.
- Hasonlóságok rögzítése: A képzés célja a hasonló kódrészletek (hasonló funkcionalitású) egymáshoz közeli elhelyezése a vektortérben. Ez lehetővé teszi olyan feladatok elvégzését, mint a hasonló kód keresése vagy a funkciók összehasonlítása.
Íme egy leegyszerűsített Python-példa arra vonatkozóan, hogyan dolgozhatja fel a kódot a beágyazáshoz:
import ast
def tokenize_code(code_string):
tree = ast.parse(code_string)
tokens = []
for node in ast.walk(tree):
if isinstance(node, ast.Name):
tokens.append(node.id)
elif isinstance(node, ast.Str):
tokens.append('STRING')
elif isinstance(node, ast.Num):
tokens.append('NUMBER')
# Add more node types as needed
return tokens
# Example usage
code = """
def greet(name):
print("Hello, " + name + "!")
"""
tokens = tokenize_code(code)
print(tokens)
# Output: ['def', 'greet', 'name', 'print', 'STRING', 'name', 'STRING']
Ez a tokenizált reprezentáció azután betáplálható egy neurális hálózatba beágyazáshoz.
A kódbeágyazás meglévő megközelítései
A kódbeágyazás meglévő módszerei három fő kategóriába sorolhatók:
Token-alapú módszerek
A token alapú módszerek a kódot lexikális tokenek sorozataként kezelik. Olyan technikák, mint a Term Frequency-Inverse Document Frequency (TF-IDF) és a mély tanulási modellek, mint pl. CodeBERT ebbe a kategóriába tartoznak.
Fa alapú módszerek
A fa alapú módszerek absztrakt szintaxisfákká (AST) vagy más fastruktúrákká elemezik a kódot, rögzítve a kód szintaktikai és szemantikai szabályait. Ilyenek például a faalapú neurális hálózatok és modellek, mint pl code2vec és a ASTNN.
Grafikon alapú módszerek
A gráf alapú módszerek kódból grafikonokat, például vezérlőfolyamat-gráfokat (CFG-k) és adatfolyam-gráfokat (DFG-k) készítenek a kód dinamikus viselkedésének és függőségeinek ábrázolására. GraphCodeBERT figyelemre méltó példa.
TransformCode: A kódbeágyazás keretrendszere
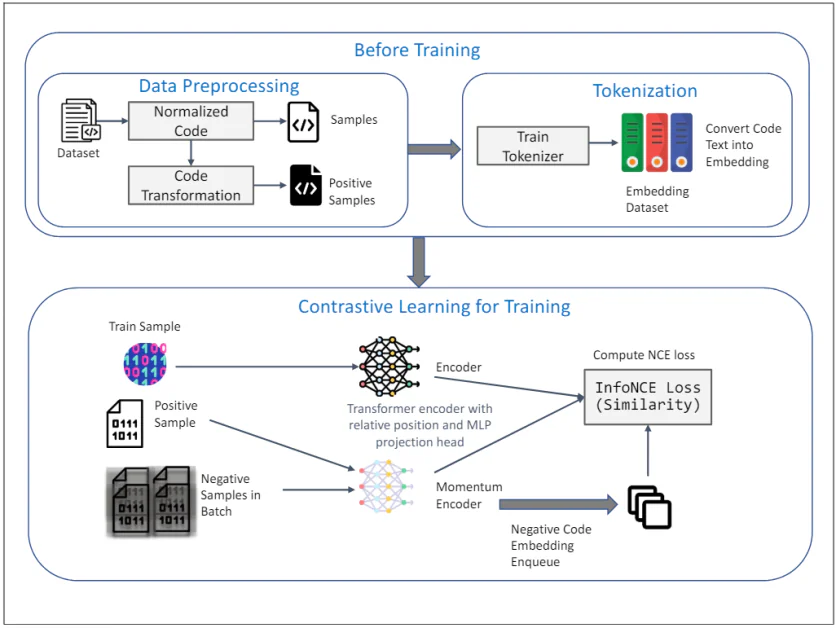
TransformCode: A kódbeágyazás felügyelet nélküli tanulása
TransformCode egy olyan keretrendszer, amely a meglévő módszerek korlátait kezeli a kódbeágyazások kontrasztív tanulási módon történő megtanulásával. Kódoló- és nyelv-agnosztikus, ami azt jelenti, hogy bármilyen kódolómodellt képes kihasználni, és bármilyen programozási nyelvet kezel.
A fenti diagram a TransformCode keretrendszerét szemlélteti a kódbeágyazás kontrasztív tanulással történő felügyelet nélküli tanulására. Két fő fázisból áll: Edzés előtt és a Kontrasztív tanulás a képzéshez. Itt található az egyes összetevők részletes magyarázata:
Edzés előtt
1. Adatok előfeldolgozása:
- Adatbázis: A kezdeti bemenet egy kódrészleteket tartalmazó adatkészlet.
- Normalizált kód: A kódrészletek normalizáláson mennek keresztül a megjegyzések eltávolítása és a változók szabványos formátumra történő átnevezése érdekében. Ez segít csökkenteni a változó elnevezésének a tanulási folyamatra gyakorolt hatását, és javítja a modell általánosíthatóságát.
- Kód átalakítás: A normalizált kódot ezután különféle szintaktikai és szemantikai transzformációkkal transzformáljuk pozitív minták generálására. Ezek az átalakítások biztosítják, hogy a kód szemantikai jelentése változatlan maradjon, változatos és robusztus mintákat biztosítva a kontrasztív tanuláshoz.
2. Tokenizálás:
- Vonat tokenizátor: A kódadatkészleten egy tokenizátor van betanítva, hogy kódszöveget beágyazásokká alakítson. Ez magában foglalja a kód felosztását kisebb egységekre, például tokenekre, amelyeket a modell képes feldolgozni.
- Adatkészlet beágyazása: A betanított tokenizátor a teljes kódadatkészletet beágyazásokká alakítja, amelyek a kontrasztív tanulási fázis bemeneteként szolgálnak.
Kontrasztív tanulás a képzéshez
3. Képzési folyamat:
- Vonatminta: A betanítási adatkészletből egy minta kerül kiválasztásra lekérdezési kód reprezentációként.
- Pozitív minta: A megfelelő pozitív minta a lekérdezési kód transzformált változata, amelyet az adat-előfeldolgozási fázis során kaptunk.
- Negatív minták kötegben: A negatív minták az aktuális mini kötegben lévő összes többi kódminta, amely eltér a pozitív mintától.
4. Encoder és Momentum Encoder:
- Transzformátor kódoló relatív pozícióval és MLP vetítőfejjel: Mind a lekérdezés, mind a pozitív minták egy Transformer kódolóba kerülnek. A kódoló relatív pozíciókódolást tartalmaz a szintaktikai struktúra és a kódban lévő tokenek közötti kapcsolatok rögzítésére. Egy MLP (Multi-Layer Perceptron) vetítőfejet használnak a kódolt reprezentációk leképezésére egy alacsonyabb dimenziós térre, ahol a kontrasztív tanulási célt alkalmazzák.
- Momentum kódoló: Egy momentum kódoló is használatos, amelyet a lekérdező kódoló paramétereinek mozgóátlaga frissít. Ez segít megőrizni az ábrázolások konzisztenciáját és sokszínűségét, megakadályozva a kontrasztív veszteség összeomlását. A negatív mintákat ezzel a momentumkódolóval kódolják, és sorba állítják a kontrasztív tanulási folyamathoz.
5. Kontrasztív tanulási cél:
- Számítsa ki az információs NCE-veszteséget (hasonlóság): A InfoNCE (Noise Contrastive Estimation) veszteség úgy van kiszámítva, hogy maximalizálja a hasonlóságot a lekérdezés és a pozitív minták között, miközben minimalizálja a hasonlóságot a lekérdezés és a negatív minták között. Ez a cél biztosítja, hogy a tanult beágyazások megkülönböztetőek és robusztusak legyenek, rögzítve a kódrészletek szemantikai hasonlóságát.
A teljes keretrendszer a kontrasztív tanulás erősségeit használja ki, hogy értelmes és robusztus kódbeágyazásokat tanuljon meg címkézetlen adatokból. Az AST transzformációk és a momentumkódoló használata tovább javítja a tanult reprezentációk minőségét és hatékonyságát, így a TransformCode hatékony eszköz a különféle szoftverfejlesztési feladatokhoz.
A TransformCode legfontosabb jellemzői
- Rugalmasság és alkalmazkodóképesség: Bővíthető különféle, kódreprezentációt igénylő downstream feladatokra.
- Hatékonyság és skálázhatóság: Nem igényel nagy modellt vagy kiterjedt képzési adatokat, bármilyen programozási nyelvet támogat.
- Felügyelt és felügyelt tanulás: Mindkét tanulási forgatókönyvre alkalmazható feladatspecifikus címkék vagy célok beépítésével.
- Állítható paraméterek: A kódolóparaméterek száma beállítható a rendelkezésre álló számítási erőforrások alapján.
A TransformCode bemutatja az AST transzformációnak nevezett adatbővítési technikát, amely szintaktikai és szemantikai transzformációkat alkalmaz az eredeti kódrészletekre. Ez változatos és robusztus mintákat generál a kontrasztív tanuláshoz.
A kódbeágyazások alkalmazásai
A kódbeágyazások forradalmasították a szoftverfejlesztés különböző aspektusait azáltal, hogy a kódot szöveges formátumból a gépi tanulási modellek által használható numerikus ábrázolássá alakították át. Íme néhány kulcsfontosságú alkalmazás:
Továbbfejlesztett kódkeresés
A kódkeresés hagyományosan a kulcsszóegyeztetésen alapult, ami gyakran irreleváns eredményekhez vezetett. A kódbeágyazás lehetővé teszi a szemantikus keresést, ahol a kódrészletek funkciói hasonlóságuk alapján rangsorolódnak, még akkor is, ha eltérő kulcsszavakat használnak. Ez jelentősen javítja a nagy kódbázisokon belüli releváns kód megtalálásának pontosságát és hatékonyságát.
Intelligensebb kódkiegészítés
A kódkiegészítő eszközök releváns kódrészleteket javasolnak az aktuális környezet alapján. A kódbeágyazások kihasználásával ezek az eszközök pontosabb és hasznosabb javaslatokat adhatnak az írott kód szemantikai jelentésének megértése révén. Ez gyorsabb és produktívabb kódolási élményt jelent.
Automatizált kódjavítás és hibafelismerés
A kódbeágyazások felhasználhatók olyan minták azonosítására, amelyek gyakran jelzik a kód hibáit vagy nem megfelelő hatékonyságát. A kódrészletek és az ismert hibaminták közötti hasonlóság elemzésével ezek a rendszerek automatikusan javításokat javasolhatnak, vagy kiemelhetik azokat a területeket, amelyek további vizsgálatot igényelhetnek.
Továbbfejlesztett kódösszesítés és dokumentáció generálás
A nagy kódbázisokból gyakran hiányzik a megfelelő dokumentáció, ami megnehezíti az új fejlesztők számára, hogy megértsék működésüket. A kódbeágyazások tömör összefoglalásokat készíthetnek, amelyek megragadják a kód funkcióinak lényegét. Ez nemcsak javítja a kód karbantarthatóságát, hanem megkönnyíti a tudásátadást is a fejlesztőcsapaton belül.
Továbbfejlesztett kódellenőrzések
A kódellenőrzés kulcsfontosságú a kódminőség megőrzéséhez. A kódbeágyazás segítheti az ellenőröket azáltal, hogy kiemeli a lehetséges problémákat, és fejlesztéseket javasol. Ezenkívül megkönnyíthetik a különböző kódverziók összehasonlítását, hatékonyabbá téve a felülvizsgálati folyamatot.
Többnyelvű kódfeldolgozás
A szoftverfejlesztés világa nem korlátozódik egyetlen programozási nyelvre. A kódbeágyazások ígéretesek a többnyelvű kódfeldolgozási feladatok megkönnyítésében. A különböző nyelveken írt kódok közötti szemantikai kapcsolatok rögzítésével ezek a technikák olyan feladatokat tesznek lehetővé, mint a kódkeresés és a programozási nyelvek elemzése.











