אבטחת סייבר
למה התקפות תמונה אדברסריות אינן בדיחה
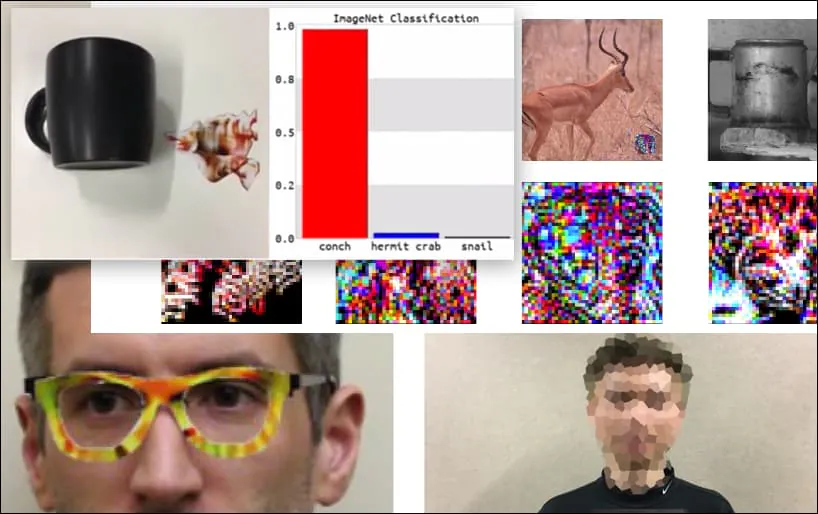
תקיפת מערכות זיהוי תמונות עם תמונות אדברסריות מותאמות הוגדרה כרעיון משעשע אך טריוויאלי במשך חמש השנים האחרונות. עם זאת, מחקר חדש מאוסטרליה מצביע על כך שהשימוש הקל במאגרי נתונים פופולריים ביותר לפרויקטים מסחריים של AI יכול ליצור בעיה ביטחונית חדשה וקבועה.
במשך מספר שנים, קבוצת אקדמאים באוניברסיטת אדלייד מנסה להסביר משהו חשוב מאוד על עתיד them מערכות זיהוי תמונות המבוססות על AI.
זה משהו שיהיה קשה (וגם יקר מאוד) לתקן כרגע, ואשר יהיה בלתי נסבל לתקן פעם נוספת, כאשר מגמות נוכחיות במחקר זיהוי תמונות יוכלו להתפתח לפרויקטים מסחריים ותעשייתיים בתוך 5-10 שנים.
לפני שנכנסים לפרטים, בואו נביט בפרח המסווג כנשיא ברק אובמה, מאחד מששת הסרטונים שפרסמה הקבוצה בדף הפרויקט:
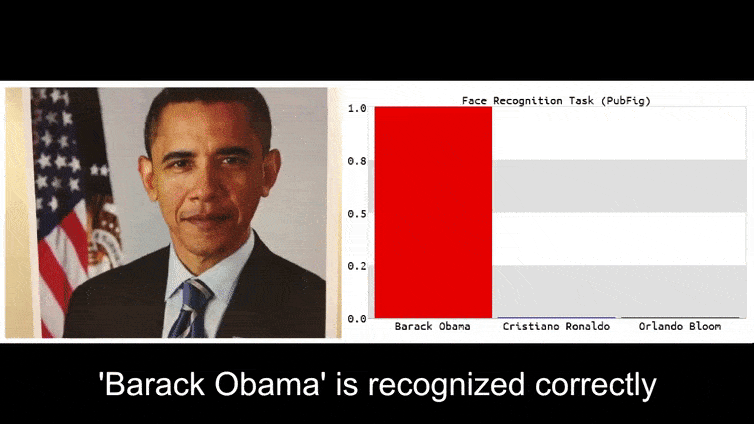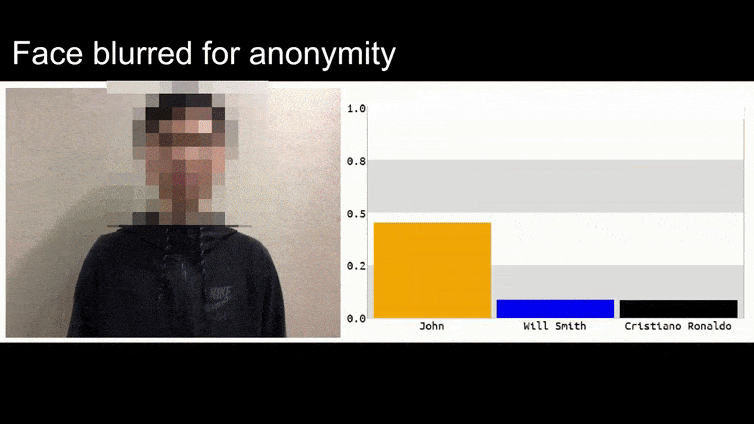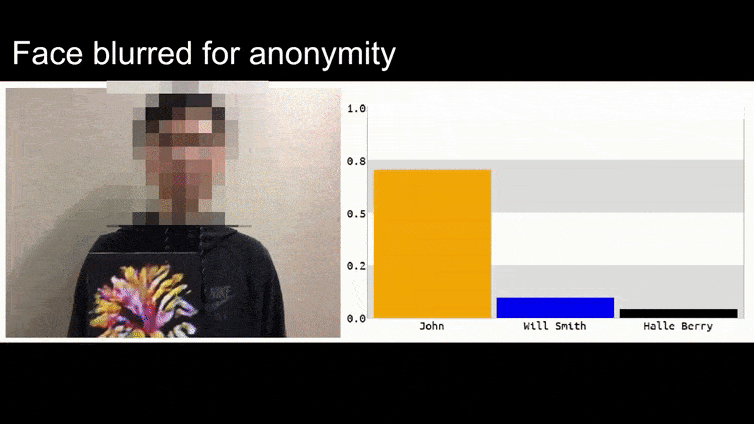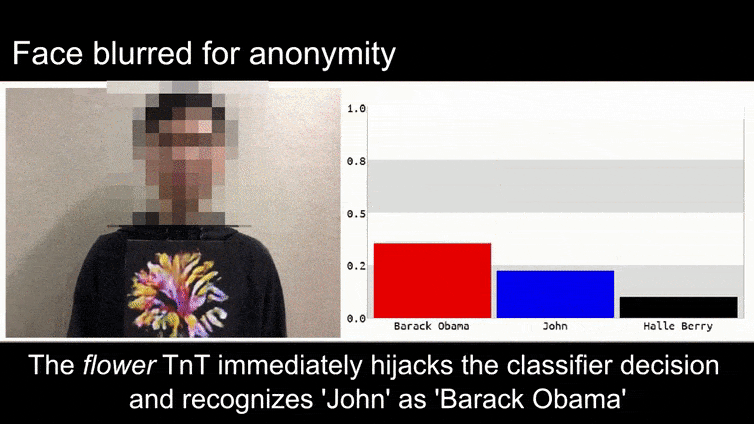
Source: https://www.youtube.com/watch?v=Klepca1Ny3c
בתמונה לעיל, מערכת זיהוי פנים שברור שיכולה לזהות את ברק אובמה מוטעית לוודאות 80% שאדם אנונימי האוחז תמונה אדברסרית מודפסת של פרח גם הוא ברק אובמה. המערכת לא אכפת לה שה”פנים המזויפות” נמצאות על החזה של הנושא, במקום על כתפיו.
על אף שזה מרשים שהחוקרים הצליחו לבצע סוג זה של לכידת זהות על ידי יצירת תמונה קוהרנטית (פרח) במקום רק רעש אקראי, נראה שחשיפות מגוחכות כאלו צצות לעיתים קרובות במחקר ביטחוני על ראייה ממוחשבת. למשל, אותם משקפיים בעלי דוגמאות מוזרות שהצליחו לרמות זיהוי פנים בשנת 2016, או תמונות אדברסריות מותאמות שמנסות לשנות את משמעותן של שלטי דרך.
אם אתם מעוניינים, המודל CNN המותקף בדוגמה לעיל הוא VGGFace (VGG-16), שאומן על מאגר הנתונים PubFig של אוניברסיטת קולומביה. דוגמאות התקפה אחרות שפיתחו החוקרים השתמשו במשאבים שונים בשילובים שונים.
<img class="wp-image-178920 size-full" src="https://www.unite.ai/wp-content/uploads/2021/11/keyboard-to-conch.gif" alt="מקלדת מסווגת מחדש כקונכייה, במודל WideResNet50 על ImageNet. החוקרים גם ודאו שהמודל אינו מוטה לטובת קונכיות. ראו את הווידאו המלא להדגמות נוספות בhttps://www.youtube.com/watch?v=dhTTjjrxIcU” width=”800″ height=”270″ /> מקלדת מסווגת מחדש כקונכייה, במודל WideResNet50 על ImageNet. החוקרים גם ודאו שהמודל אינו מוטה לטובת קונכיות. ראו את הווידאו המלא להדגמות נוספות בhttps://www.youtube.com/watch?v=dhTTjjrxIcU
זיהוי תמונות כווקטור התקפה מתפתח
התקפות הרבות והמרשימות שהחוקרים מתארים ומדגימים אינן ביקורת על מאגרי נתונים ספציפיים או ארכיטקטורות למידת מכונה המשתמשות בהם. גם לא ניתן להגן נגדן בקלות על ידי החלפת מאגרי נתונים או מודלים, אימון מחדש של מודלים, או פתרונות “פשוטים” אחרים שגורמים למעניקי ML ללעוג להדגמות ספורדיות של סוג זה של תרמית.
במקום זאת, התקפות הקבוצה ממחישות חולשה מרכזית בכל הארכיטקטורה הנוכחית של פיתוח AI לזיהוי תמונות; חולשה שעלולה לחשוף מערכות זיהוי תמונות רבות להשפעה קלה של תוקפים, ולשים את האמצעים המגינים בעמדת נחיתות.
דמיינו את התקפות התמונות האדברסריות האחרונות (כגון הפרח לעיל) המוספות כ”ניצולים Zero-Day” למערכות אבטחה עתידיות, בדומה לאיך מערכות אנטי-וירוס ואנטי-מאלוור מעדכנות את הגדרות הווירוסים שלהן כל יום.
הפוטנציאל לתקפות תמונות אדברסריות חדשות יהיה בלתי נדלה, שכן הארכיטקטורה הבסיסית של המערכת לא צפתה בעיות מדורסטרים, כפי שקרה עם האינטרנט, הבאג של המילניום ומגדל פיזה הנטוי.
באיזו דרך, אז, אנו מכינים את הסצנה לכך?
קבלת נתונים להתקפה
תמונות אדברסריות כגון דוגמת ה”פרח” לעיל מופקות על ידי גישה למאגרי הנתונים שאימנו את המודלים. אינכם זקוקים לגישה “מועדפת” לנתונים (או ארכיטקטורות מודל), שכן מאגרי הנתונים הפופולריים ביותר (ומודלים רבים) זמינים בשפע ובזרם עדכני.
למשל, ענק המאגרים של ראייה ממוחשבת, ImageNet, זמין להורדה בכל הגרסאות שלו, תוך עקיפת הגבלות הרגילות, והפצת איברים משניים חשובים, כגון קבוצות אימון.

Source: https://academictorrents.com
אם יש לכם את הנתונים, אתם יכולים (כפי שהחוקרים מאדלייד מציינים) ל”הפוך” את כל מאגר נתונים פופולרי, כגון CityScapes, או CIFAR.
במקרה של PubFig, המאגר שאיפשר את “פרח אובמה” בדוגמה הקודמת, אוניברסיטת קולומביה טיפלה במגמה גוברת של בעיות זכויות יוצרים סביב הפצת מאגרי נתונים של תמונות, על ידי הוראה לחוקרים לשחזר את המאגר דרך קישורים מקוריים, במקום להפיץ את האוסף ישירות, תוך ציון ‘זה נראה כמו הדרך שבה מאגרי נתונים רבים אחרים מתפתחים’.
במרבית המקרים, זה לא הכרחי: Kaggle מעריך כי עשרת מאגרי הנתונים הפופולריים ביותר בראייה ממוחשבת הם: CIFAR-10 ו-CIFAR-100 (שניהם זמינים להורדה); CALTECH-101 ו-256 (שניהם זמינים, וכרגע זמינים גם כטורנט); MNIST (זמין רשמית, גם על טורנט); ImageNet (ראו לעיל); Pascal VOC (זמין, גם על טורנט); MS COCO (זמין, וגם על טורנט); Sports-1M (זמין); ו-YouTube-8M (זמין).
זמינות זו גם מייצגת את טווח הרחב יותר של מאגרי נתונים לראייה ממוחשבת, שכן העמימות היא מוות בתרבות פיתוח קוד פתוח.
בכל מקרה, המחסור במאגרי נתונים ניהוליים, עלות גבוהה של פיתוח קבוצת תמונות, התלות ב”אהובים הישנים”, והנטייה לעדכן מאגרי נתונים ישנים – כל אלו מחמירים את הבעיה שתוארה בנייר החדש.
ביקורות טיפוסיות על שיטות התקפת תמונות אדברסריות
הביקורת התכופה והעקבית ביותר של מהנדסי למידת מכונה נגד יעילות שיטות התקפת תמונות אדברסריות היא שההתקפה ספציפית למאגר נתונים מסוים, מודל מסוים, או שניהם; שהיא אינה “ניתנת לכלל” למערכות אחרות; ולפיכך, מייצגת רק איום טריוויאלי.
התלונה השנייה בתכיפות היא שהתקפת התמונה האדברסרית היא ‘תיבה לבנה’, מה שאומר שתזדקקו לגישה ישירה לסביבת האימון או לנתונים. זה אכן סצנריו בלתי סביר, במרבית המקרים – למשל, אם הייתם רוצים לנצל את תהליך האימון של מערכות זיהוי פנים של משטרת לונדון, הייתם צריכים לפרוץ לNEC, הן דרך קונסול או גרזן.
ה’DNA’ הארוך-טווח של מאגרי נתונים פופולריים לראייה ממוחשבת
באשר לביקורת הראשונה, עלינו לשקל לא רק שמעט מאגרי נתונים לראייה ממוחשבת שולטים בתעשייה, אלא גם שהם “אגנוסטיים לפלטפורמה” וניתנים להעברה.
תלוי ביכולותיה, כל ארכיטקטורה של ראייה ממוחשבת תמצא מספר מאפיינים של אובייקטים ומחלקות במאגר הנתונים ImageNet. חלק מהארכיטקטורות עשויות למצוא יותר מאפיינים מאחרות, או ליצור קשרים יותר מועילים, אך כולן תמצאו לפחות את המאפיינים ברמה הגבוהה:

נתוני ImageNet, עם מספר הזיהויים הניתנים – ‘מאפיינים ברמה גבוהה’.
אלו ה”מאפיינים ברמה גבוהה” שמבדילים ו”מטביעים” מאגר נתונים, ואשר מהווים “וו-הוקים” אמינים לתליית שיטת התקפת תמונות אדברסריות ארוכת-טווח, שיכולה לחצות מערכות שונות, ולגדול במקביל עם המאגר “הישן” ככל שהאחרון ממשיך להתקיים במחקרים ומוצרים חדשים.
ארכיטקטורה מתוחכמת יותר תיצור זיהויים מדויקים ומורכבים יותר, מאפיינים ומחלקות:

אולם, ככל שיותר מתבססת שיטת התקפת התמונה האדברסרית על מאפיינים נמוכים (כלומר “גבר לבן צעיר” במקום “פנים”), כן תהיה פחות יעילה במעבר לארכיטקטורות מאוחרות יותר, שמשתמשות ב
התקפות אדברסריות על מודלים ‘מאופסים’, מוכונים מראש
מה קורה במקרים שבהם אתם פשוט מורידים מודל מוכון מראש, שאומן במקור על מאגר נתונים פופולרי מאוד, ונותנים לו נתונים חדשים לגמרי?
המודל כבר אומן על (למשל) ImageNet, וכל מה שנותר הוא המשקולות, שעשויות להיות תוצאה של שבועות או חודשים של אימון, וכעת מוכנות לעזור לכם לזהות אובייקטים דומים לאלו שהיו בנתונים המקוריים (שכעת נעדרים).

עם הנתונים המקוריים המוסרים מהארכיטקטורת האימון, מה שנותר הוא ‘נטיית’ המודל לסווג אובייקטים בדרך שלמד, מה שבעצם יגרום לרבים מה’חתימות’ המקוריות להיווצר מחדש ולהיות פגיעים שוב לאותן שיטות התקפת תמונות אדברסריות הישנות.
אותם המשקולות שימושיים. בלעדי הנתונים או המשקולות, אתם בעצם מחזיקים בארכיטקטורה ריקה עם אף נתון. אתם תצטרכו לאמנה מחדש, בעלות גבוהה של זמן ומשאבי חישוב, בדומה למה שעשו המחברים המקוריים (כנראה עם חומרה חזקה יותר ותקציב גבוה יותר משלכם).
הבעיה היא שהמשקולות כבר מאוד מוכנות ועמידות. אף על פי שהן יתאימו עצמן במידה מסוימת באימון, הן יתנהגו באופן דומה על נתונים חדשים כפי שהתנהגו על הנתונים המקוריים, ויפיקו “חתימות” שמערכת התקפת תמונות אדברסריות יכולה להיאחז בהן.
בטווח הארוך, זה גם שומר על ה”DNA” של מאגרי נתונים לראייה ממוחשבת, שהם שנים-עשר או יותר שנים, ואשר עשויים לעבור התפתחות משמעותית ממאמץ פתוח-מקור דרך פרויקטים מסחריים – אפילו כאשר הנתונים המקוריים הושלכו בתחילת הפרויקט.
אין צורך ב’תיבה לבנה’
באשר לביקורת השנייה הנפוצה על שיטות התקפת תמונות אדברסריות, מחברי הנייר החדש מצאו כי יכולתם לרמות מערכות זיהוי עם תמונות פרחים מותאמות היא היעילה ביותר במעבר בין ארכיטקטורות.
כשהם מציינים כי שיטתם “Universal NaTuralistic adversarial paTches” (TnT) היא הראשונה להשתמש בתמונות מוכרות (במקום רעש אקראי) כדי לרמות מערכות זיהוי תמונות, המחברים גם טוענים:
‘[TnTs] יעילות נגד מספר מערכות מובילות, החל מWideResNet50 במשימת הזיהוי הוויזואלי בקנה מידה גדול של ImageNet לדגמי VGG-face במשימת זיהוי פנים של PubFig בשני התקפות מכוונות ו לא-מכוונות.
‘TnTs יכולות להיות: i) ברמת הטבעיות המושגת [עם] גרירות המשמשות בשיטות התקפת טרויאני; ו-ii) הכלליות והיכולת להעביר דוגמאות אדברסריות לרשתות אחרות.
‘זה מעלה חששות ביטחוניות לגבי DNNs שכבר הופלו, כמו גם DNNs עתידיים, שבהם תוקפים יכולים להשתמש בפאטצ’ים של אובייקטים טבעיים-מראה לשבש מערכות רשת עצבית מבלי לפגוע במודל ולסכן גילוי.’
המחברים מציעים כי אמצעי נגד מסורתיים, כגון הורדת הדיוק של מערכת, יכולים לספק הגנה מסוימת נגד פאטצ’ים TnT, אך כי ‘TnTs עדיין יכולות לעקוף את שיטות ההגנה המוכחות, עם רוב המערכות המגינות שמשיגות 0% עמידות’.
פתרונות אפשריים אחרים כוללים למידה פדרטיבית, שבה הייחוס של תמונות הוא מוגן, וגישות חדשות שיכולות ל”אפסן” נתונים בזמן אימון, כגון זו שהוצעה לאחרונה על ידי אוניברסיטת נאנג’ינג לאווירונאוטיקה ואסטרונאוטיקה.
אפילו במקרים אלו, יהיה חשוב לאמן על נתונים חדשים אמיתיים – כעת, התמונות והתיוגים הנלווים במאגרי הנתונים הפופולריים ביותר הם כה משולבים במחזורי פיתוח ברחבי העולם, עד שהם מזכירים יותר תוכנה מאשר נתונים; תוכנה שלעיתים קרובות לא עודכנה במשך שנים.
מסקנה
התקפות תמונות אדברסריות מתאפשרות לא רק על ידי פרקטיקות קוד פתוח, אלא גם על ידי תרבות פיתוח AI מסחרית, שמניעה אותה לשימוש חוזר במאגרי נתונים פופולריים לראייה ממוחשבת, מסיבות רבות: הם הוכחו כיעילים; הם זולים יותר מ”להתחיל מאפס”; והם מתוחזקים ומעודכנים על ידי מוחות וארגונים מובילים באקדמיה ובתעשייה, ברמות מימון וצוות שקשה לחברה בודדת לשחזר.
בנוסף, במקרים רבים, שבהם הנתונים אינם מקוריים (בניגוד לCityScapes), התמונות נאספו לפני המחלוקות האחרונות סביב פרטיות ופרקטיקות איסוף נתונים, מה שהותיר את מאגרי הנתונים הישנים יותר בסוג של פורגטוריום חצי-חוקי שיכול להיראות כ”נמל בטוח” מנקודת מבטה של חברה.
TnT Attacks! Universal Naturalistic Adversarial Patches Against Deep Neural Network Systems משותף על ידי Bao Gia Doan, Minhui Xue, Ehsan Abbasnejad, Damith C. Ranasinghe מאוניברסיטת אדלייד, יחד עם Shiqing Ma ממחלקת מדעי המחשב באוניברסיטת ראטגרס.
עודכן ב-1 בדצמבר 2021, 7:06, GMT+2 – תוקן טיפוגרפיה.












