בינה מלאכותית
AudioSep : הפרד את כל מה שאתה מתאר
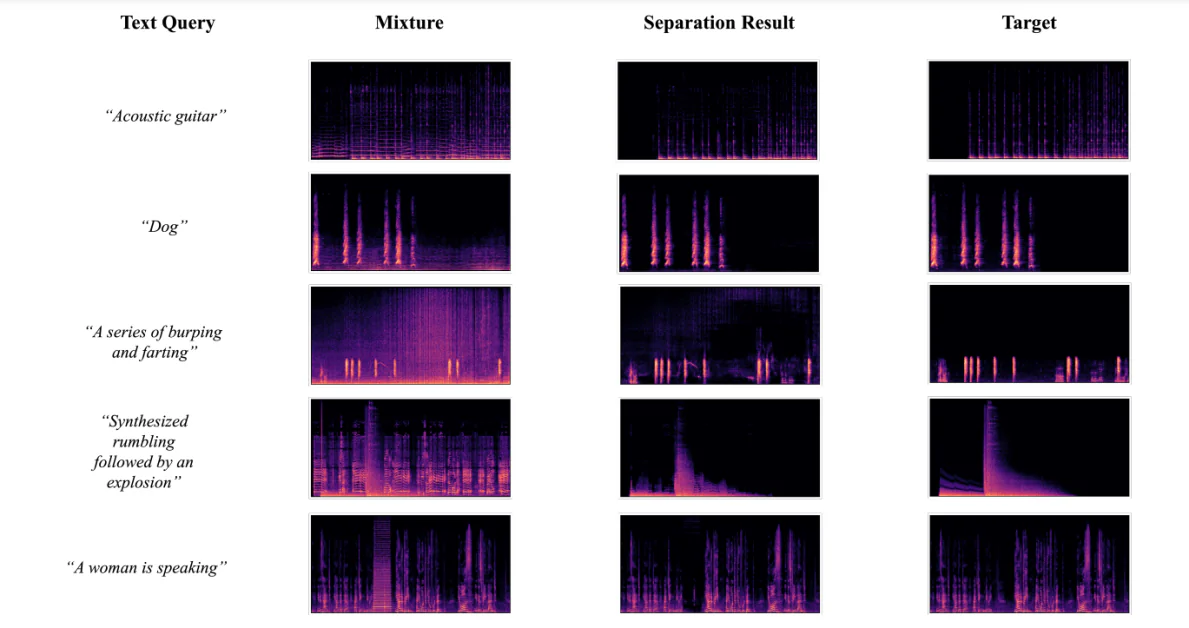
LASS או Language-queried Audio Source Separation הוא הפרדיגמה החדשה ל- CASA או Computational Auditory Scene Analysis שמטרתה להפריד קול מטרה מתוך תערובת של אודיו באמצעות שאילתה בשפה טבעית שמספקת ממשק מקורי וגמיש למשימות ויישומים דיגיטליים של אודיו. על אף שהמסגרות LASS התקדמו באופן משמעותי בשנים האחרונות במונחים של השגת ביצועים רצויים על מקורות אודיו ספציפיים כגון כלי נגינה, הן אינן מסוגלות להפריד את האודיו המטרה בתחום הפתוח.
AudioSep, הוא מודל יסודי שמטרתו לפתור את המגבלות הנוכחיות של מסגרות LASS על ידי אפשרות הפרדת האודיו המטרה באמצעות שאילתות בשפה טבעית. מפתחי מסגרת AudioSep הכשירו את המודל באופן נרחב על מגוון רחב של מאגרי נתונים רב-מודאליים בקנה מידה גדול, והעריכו את ביצועי המסגרת על מגוון רחב של משימות אודיו, כולל הפרדת כלי נגינה, הפרדת אירועי אודיו, ושיפור הדיבור בין היתר. ביצועי AudioSep מספקים את הסטנדרטים, כאשר הם מדגימים יכולות למידה מרשימות במצב zero-shot ומספקים ביצועי הפרדת אודיו חזקים.
במאמר זה, נעמיק יותר בפעולת מסגרת AudioSep, כאשר נעריך את ארכיטקטורת המודל, המאגרים ששימשו לאימון והערכה, והמושגים החשובים המעורבים בפעולת מודל AudioSep. ולכן, התחלנו עם מבוא בסיסי למסגרת CASA.
CASA, USS, QSS, LASS Frameworks : היסוד ל- AudioSep
מסגרת CASA או Computational Auditory Scene Analysis היא מסגרת המשמשת מפתחים לע












