Intelligence artificielle
La Révolution MoE : Comment les Mécanismes de Routage Avancés et la Spécialisation Transforment les Modèles de Langage
En quelques années, les modèles de langage à grande échelle (LLM) sont passés de millions à des centaines de milliards de paramètres, montrant les progrès remarquables dans notre capacité à concevoir et à mettre à l’échelle des systèmes d’IA massifs. Ces systèmes massifs ont livré des capacités étonnantes telles que la rédaction de textes fluides, la génération de code, la résolution de problèmes complexes et l’engagement dans des dialogues similaires à ceux des humains. Mais cette mise à l’échelle rapide a un coût important. La formation et l’exécution de tels modèles énormes consomment des quantités extraordinaires de puissance de calcul, d’énergie et de capital. La stratégie “plus grand est mieux” qui a alimenté les progrès commence à montrer ses limites. En réponse à ces contraintes croissantes, une architecture d’IA connue sous le nom de Mélange d’Experts (MoE) progresse pour offrir un chemin plus intelligent et plus efficace pour mettre à l’échelle les modèles de langage à grande échelle. Au lieu de dépendre d’un réseau massif et toujours actif, MoE divise le modèle en une collection de sous-réseaux spécialisés ou “experts”, chacun formé pour gérer des types de données ou des tâches spécifiques. Grâce à un routage intelligent, le modèle active uniquement les experts les plus pertinents pour chaque entrée, réduisant ainsi la charge de calcul tout en maintenant ou en améliorant les performances. Cette capacité à combiner la mise à l’échelle avec l’efficacité fait de MoE l’un des paradigmes émergents les plus définisseurs dans l’IA. Cet article explore comment les mécanismes de routage avancés et la spécialisation conduisent à cette transformation et ce que cela signifie pour l’avenir des systèmes intelligents.
Comprendre l’Architecture de Base
L’idée derrière le Mélange d’Experts (MoE) n’est pas nouvelle. Elle remonte aux méthodes d’apprentissage d’ensemble des années 1990. Ce qui a changé, c’est la technologie qui la rend possible. Ce n’est que ces dernières années que les progrès de l’hardware et des algorithmes de routage ont rendu pratique l’intégration de ce concept dans les modèles de langage Transformer modernes.
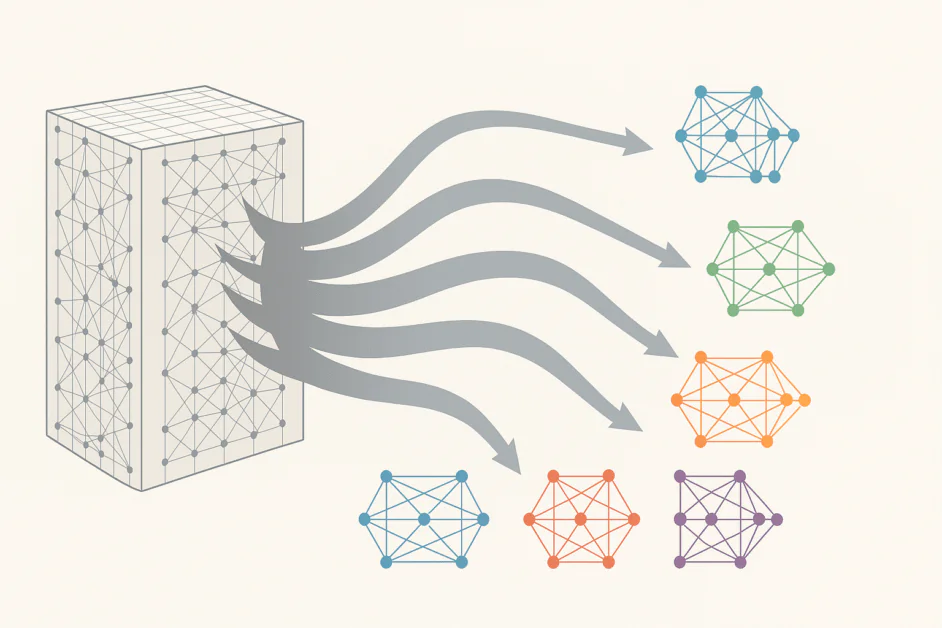
En son essence, MoE redéfinit un grand réseau neuronal comme une collection de sous-réseaux plus petits et spécialisés, chacun formé pour gérer un type de données ou de tâches spécifiques. Plutôt que d’activer tous les paramètres pour chaque entrée, MoE introduit un mécanisme de routage qui décide quels experts sont les plus pertinents pour un jeton ou une séquence donnés. Le résultat est un modèle qui n’utilise qu’une fraction de ses paramètres à tout moment, réduisant ainsi de manière spectaculaire la demande de calcul tout en préservant, voire en améliorant, les performances.
En pratique, ce changement architectural permet aux chercheurs de mettre à l’échelle les modèles à des milliers de milliards de paramètres sans nécessiter une augmentation proportionnelle des ressources de calcul. Il remplace les couches feedforward denses traditionnelles par un système plus intelligent et dynamique. Chaque couche MoE contient plusieurs experts, généralement des réseaux feedforward plus petits, et un routeur ou réseau de contrôle qui décide quels experts doivent traiter chaque pièce d’entrée. Le routeur agit comme un chef de projet, envoyant des questions pertinentes à chaque expert. Au fil du temps, le système apprend quels experts performe le mieux pour différents types de problèmes, affinant ainsi sa stratégie de routage lors de la formation.
Ce design offre une combinaison frappante d’échelle et d’efficacité. Par exemple, DeepSeek V3, l’un des modèles MoE les plus avancés, emploie un nombre étonnant de 685 milliards de paramètres mais n’en active qu’une petite partie pendant l’inférence. Il offre les performances d’un modèle massif avec des exigences computationnelles et énergétiques significativement plus faibles.
L’Évolution des Mécanismes de Routage
Le routeur est au cœur de MoE, déterminant quels experts traitent chaque entrée. Les premiers modèles utilisaient des stratégies simples, sélectionnant les deux ou trois experts en fonction des poids appris. Les systèmes modernes sont nettement plus sophistiqués.
Aujourd’hui, les mécanismes de routage dynamiques ajustent le nombre d’experts activés en fonction de la complexité de l’entrée. Une question simple peut nécessiter un seul expert, tandis que des tâches de raisonnement difficiles peuvent activer plusieurs experts. DeepSeek-V2 a mis en œuvre un routage limité par appareil pour contrôler les coûts de communication sur le matériel distribué. DeepSeek-V3 a été pionnier dans les stratégies sans perte auxiliaire qui permettent une spécialisation d’experts plus riche sans dégradation des performances.
Des routeurs avancés agissent désormais comme des gestionnaires de ressources intelligents, ajustant les stratégies de sélection en fonction des caractéristiques d’entrée, de la profondeur du réseau ou de la rétroaction de performance en temps réel. Certains chercheurs explorent l’apprentissage par renforcement pour optimiser les performances à long terme. Des techniques comme la fermeture douce permettent une sélection d’experts plus fluide, tandis que la distribution probabiliste utilise des méthodes statistiques pour optimiser les affectations.
La Spécialisation Stimule les Performances
La promesse fondamentale de MoE est que la spécialisation profonde surpasse la généralisation large. Chaque expert se concentre sur la maîtrise de domaines spécifiques plutôt que d’être médiocre dans tout. Lors de la formation, les mécanismes de routage dirigent systématiquement certains types d’entrée vers des experts spécifiques, créant ainsi une boucle de rétroaction puissante. Certains experts excellent dans le codage, d’autres dans la terminologie médicale, et d’autres dans l’écriture créative.
Cependant, atteindre cet objectif présente des défis. Les approches traditionnelles d’équilibrage de charge peuvent ironiquement entraver la spécialisation en imposant une utilisation uniforme des experts. Cependant, le domaine progresse rapidement. Des études révèlent que les modèles MoE à grain fin présentent une spécialisation claire, avec différents experts dominants dans leurs domaines respectifs. Des études confirment que les mécanismes de routage jouent un rôle actif dans la formation de cette division du travail architecturale.
Les stratégies qui emploient des experts clés de domaine ont démontré des améliorations de performances notables. Par exemple, des chercheurs ont rapporté un gain de précision de 3,33 pour cent sur le benchmark AIME2024. Lorsque la spécialisation fonctionne, les résultats sont remarquables. DeepSeek V3 surpasse GPT-4o sur la plupart des benchmarks de langage naturel et mène sur toutes les tâches de raisonnement mathématique et de codage, un jalon impressionnant pour un modèle open-source.
Impact Pratique sur les Capacités du Modèle
La révolution MoE a apporté des améliorations tangibles aux capacités de base du modèle. Les modèles peuvent désormais gérer des contextes plus longs de manière plus efficace ; à la fois DeepSeek V3 et GPT-4o peuvent traiter 128K jetons en une seule entrée, avec l’architecture MoE optimisant les performances, en particulier dans les domaines techniques. C’est crucial pour des applications comme l’analyse de codebases entières ou le traitement de documents juridiques longs.
Les gains d’efficacité sont encore plus dramatiques. L’analyse suggère que DeepSeek-V3 est environ 29,8 fois moins cher par jeton par rapport à GPT-4o. Cette différence de prix rend l’IA avancée accessible à un plus large éventail d’utilisateurs et d’applications. Cela accélère considérablement la démocratisation de l’IA.
De plus, l’architecture permet un déploiement plus durable. La formation d’un modèle MoE nécessite toujours des ressources substantielles, mais le coût d’inférence nettement plus bas ouvre la voie à un modèle plus efficace et économiquement viable pour les entreprises d’IA et leurs clients.
Les Défis et le Chemin à Suivre
Malgré les avantages significatifs, MoE n’est pas sans défis. La formation peut être instable, avec des experts qui parfois ne se spécialisent pas comme prévu. Les premiers modèles ont lutté contre le “collapsus de routage“, où un expert dominait. Assurer que tous les experts reçoivent des données de formation adéquates tout en n’activant qu’un sous-ensemble nécessite un équilibre soigneux.
Le goulet d’étranglement le plus important est la charge de communication. Dans les configurations de GPU distribuées, les coûts de communication peuvent consommer jusqu’à 77 % du temps de traitement. De nombreux experts sont “trop collaboratifs”, s’activant fréquemment ensemble et forçant des transferts de données répétés à travers les accélérateurs de matériel. Cela conduit à des réévaluations fondamentales de la conception du matériel d’IA.
Les exigences de mémoire présentent un autre défi important. Même si MoE réduit les coûts de calcul pendant l’inférence, tous les experts doivent être chargés en mémoire, ce qui met à rude épreuve les appareils de bord ou les environnements à ressources limitées. L’interprétabilité reste un autre défi clé, car identifier quel expert a contribué à une sortie donnée ajoute une couche de complexité supplémentaire à l’architecture. Les chercheurs explorent désormais des méthodes pour retracer les activations d’experts et visualiser les chemins de décision, visant à rendre les systèmes MoE plus transparents et plus faciles à auditer.
Le Fond du Panier
Le paradigme du Mélange d’Experts n’est pas seulement une nouvelle architecture ; c’est une nouvelle philosophie pour construire des modèles d’IA. En combinant un routage intelligent avec une spécialisation au niveau du domaine, MoE réalise ce qui semblait contradictoire : une plus grande échelle avec moins de calcul. Même si les défis de stabilité, de communication et d’interprétabilité persistent, son équilibre d’efficacité, d’adaptabilité et de précision pointe vers l’avenir des systèmes d’IA qui ne sont pas seulement plus grands mais également plus intelligents.












