Intelligence Artificielle
Suralimenter les grands modèles linguistiques avec la prédiction multi-jetons
By
Ayush Mittal mital
Grands modèles de langage (LLM) comme GPT, LLaMA et d’autres ont pris d’assaut le monde grâce à leur capacité remarquable à comprendre et à générer du texte de type humain. Cependant, malgré leurs capacités impressionnantes, la méthode standard de formation de ces modèles, connue sous le nom de « prédiction du prochain jeton », présente certaines limites inhérentes.
Dans la prédiction du jeton suivant, le modèle est entraîné à prédire le mot suivant dans une séquence en fonction des mots précédents. Même si cette approche s’est avérée efficace, elle peut conduire à des modèles confrontés à des dépendances à long terme et à des tâches de raisonnement complexes. De plus, l’inadéquation entre le régime de formation forcé des enseignants et le processus de génération autorégressive lors de l’inférence peut entraîner des performances sous-optimales.
Un récent article de recherche de Gloeckle et coll. (2024) de Meta AI introduit un nouveau paradigme de formation appelé «prédiction multi-jetons« qui vise à pallier ces limitations et à optimiser les grands modèles linguistiques. Dans cet article, nous approfondirons les concepts fondamentaux, les détails techniques et les implications potentielles de cette recherche révolutionnaire.
Prédiction à jeton unique : l'approche conventionnelle
Avant d'entrer dans les détails de la prédiction multi-jetons, il est essentiel de comprendre l'approche conventionnelle qui a été la bête de somme du grand modèle de langage formation pendant des années – prédiction à jeton unique, également connue sous le nom de prédiction du jeton suivant.
Le paradigme de prédiction du prochain jeton
Dans le paradigme de prédiction du prochain jeton, les modèles de langage sont entraînés pour prédire le mot suivant dans une séquence en fonction du contexte précédent. Plus formellement, le modèle est chargé de maximiser la probabilité du prochain jeton xt+1, étant donné les jetons précédents x1, x2,…, xt. Cela se fait généralement en minimisant la perte d'entropie croisée :
L = -Σt log P(xt+1 | x1, x2, …, xt)
Cet objectif de formation simple mais puissant a été à la base de nombreux grands modèles de langage réussis, tels que GPT (Radford et al., 2018), BERT (Devlin et al., 2019) et leurs variantes.
Forçage des enseignants et génération autorégressive
La prédiction du prochain jeton repose sur une technique de formation appelée «professeur forçant" où le modèle reçoit la vérité terrain pour chaque futur jeton pendant la formation. Cela permet au modèle d'apprendre à partir du contexte correct et des séquences cibles, facilitant ainsi un entraînement plus stable et plus efficace.
Cependant, lors de l'inférence ou de la génération, le modèle fonctionne de manière autorégressive, prédisant un jeton à la fois en fonction des jetons générés précédemment. Cette inadéquation entre le régime de formation (forçage de l'enseignant) et le régime d'inférence (génération autorégressive) peut conduire à des écarts potentiels et à des performances sous-optimales, en particulier pour des séquences plus longues ou des tâches de raisonnement complexes.
Limites de la prédiction du prochain jeton
Bien que la prédiction du prochain jeton ait connu un succès remarquable, elle présente également certaines limites inhérentes :
- Objectif à court terme: En prédisant uniquement le prochain jeton, le modèle peut avoir du mal à capturer les dépendances à long terme ainsi que la structure et la cohérence globales du texte, conduisant potentiellement à des incohérences ou à des générations incohérentes.
- Verrouillage de modèle local: Les modèles de prédiction du jeton suivant peuvent s'accrocher à des modèles locaux dans les données d'entraînement, ce qui rend difficile la généralisation à des scénarios ou à des tâches hors distribution qui nécessitent un raisonnement plus abstrait.
- Capacités de raisonnement: Pour les tâches qui impliquent un raisonnement en plusieurs étapes, une pensée algorithmique ou des opérations logiques complexes, la prédiction du prochain jeton peut ne pas fournir suffisamment de biais ou de représentations inductives pour prendre en charge efficacement de telles capacités.
- Exemple d'inefficacité: En raison de la nature locale de la prédiction du prochain jeton, les modèles peuvent nécessiter des ensembles de données de formation plus volumineux pour acquérir les connaissances et les compétences de raisonnement nécessaires, ce qui entraîne des inefficacités potentielles des échantillons.
Ces limitations ont motivé les chercheurs à explorer des paradigmes de formation alternatifs, tels que la prédiction multi-jetons, qui visent à remédier à certaines de ces lacunes et à débloquer de nouvelles capacités pour les grands modèles de langage.
En comparant l’approche conventionnelle de prédiction du prochain jeton avec la nouvelle technique de prédiction multi-jetons, les lecteurs peuvent mieux apprécier la motivation et les avantages potentiels de cette dernière, ouvrant ainsi la voie à une exploration plus approfondie de cette recherche révolutionnaire.
Qu'est-ce que la prédiction multi-jetons ?
L’idée clé derrière la prédiction multi-jetons est d’entraîner des modèles de langage pour prédire simultanément plusieurs futurs jetons, plutôt que simplement le prochain jeton. Plus précisément, pendant la formation, le modèle est chargé de prédire les n jetons suivants à chaque position du corpus de formation, en utilisant n têtes de sortie indépendantes fonctionnant au-dessus d'un tronc de modèle partagé.
Par exemple, avec une configuration de prédiction à 4 jetons, le modèle serait entraîné pour prédire les 4 prochains jetons à la fois, compte tenu du contexte précédent. Cette approche encourage le modèle à capturer les dépendances à plus long terme et à développer une meilleure compréhension de la structure globale et de la cohérence du texte.
Un exemple de jouet
Pour mieux comprendre le concept de prédiction multi-jetons, prenons un exemple simple. Supposons que nous ayons la phrase suivante :
"Le rapide renard brun saute par-dessus le chien paresseux."
Dans l’approche standard de prédiction du prochain jeton, le modèle serait entraîné pour prédire le mot suivant en fonction du contexte précédent. Par exemple, étant donné le contexte « Le renard brun rapide saute par-dessus », le modèle serait chargé de prédire le mot suivant, « paresseux ».
Cependant, avec une prédiction multi-jetons, le modèle serait entraîné pour prédire plusieurs mots futurs à la fois. Par exemple, si nous définissons n = 4, le modèle serait entraîné pour prédire simultanément les 4 mots suivants. Dans le même contexte « Le renard brun rapide saute par-dessus le », le modèle serait chargé de prédire la séquence « chien paresseux ». (Notez l'espace après « chien » pour indiquer la fin de la phrase).
En entraînant le modèle à prédire plusieurs futurs jetons à la fois, il est encouragé à capturer les dépendances à long terme et à développer une meilleure compréhension de la structure globale et de la cohérence du texte.
Détails techniques
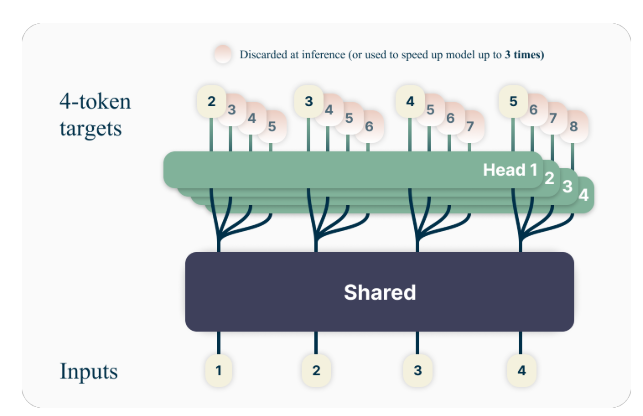
Les auteurs proposent une architecture simple mais efficace pour mettre en œuvre la prédiction multi-jetons. Le modèle se compose d'un tronc de transformateur partagé qui produit une représentation latente du contexte d'entrée, suivi de n couches de transformateurs indépendantes (têtes de sortie) qui prédisent les futurs jetons respectifs.
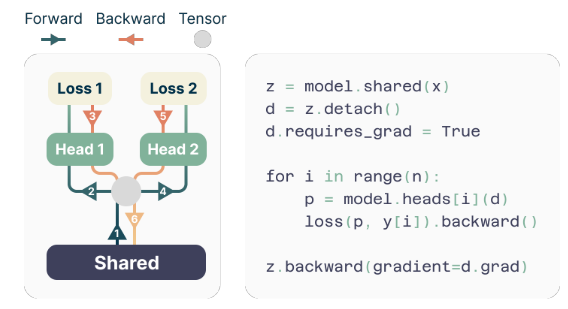
Pendant l'entraînement, les passes avant et arrière sont soigneusement orchestrées pour minimiser l'empreinte mémoire du GPU. Le tronc partagé calcule la représentation latente, puis chaque tête de sortie effectue séquentiellement son passage avant et arrière, accumulant des gradients au niveau du tronc. Cette approche évite de matérialiser simultanément tous les vecteurs logit et leurs gradients, réduisant ainsi l'utilisation maximale de la mémoire GPU de O(nV + d) à O(V + d), Où V est le taille du vocabulaire et d est le dimension de la représentation latente.
L'implémentation économe en mémoire
L'un des défis liés à la formation de prédicteurs multi-jetons est de réduire l'utilisation de la mémoire GPU. Depuis le taille du vocabulaire (V) est généralement beaucoup plus grand que le dimension de la représentation latente (D), les vecteurs logit deviennent le goulot d'étranglement de l'utilisation de la mémoire GPU.
Pour relever ce défi, les auteurs proposent une implémentation efficace en mémoire qui adapte soigneusement la séquence des opérations avant et arrière. Au lieu de matérialiser simultanément tous les logits et leurs gradients, l'implémentation calcule séquentiellement les passes avant et arrière pour chaque tête de sortie indépendante, accumulant les gradients au niveau du tronc.
Cette approche évite de stocker simultanément tous les vecteurs logit et leurs gradients en mémoire, réduisant ainsi l'utilisation maximale de la mémoire GPU de O(nV + d) à O(V + d), Où n est le nombre de futurs jetons prédits.
Avantages de la prédiction multi-jetons
Le document de recherche présente plusieurs avantages convaincants de l’utilisation de la prédiction multi-jetons pour former de grands modèles de langage :
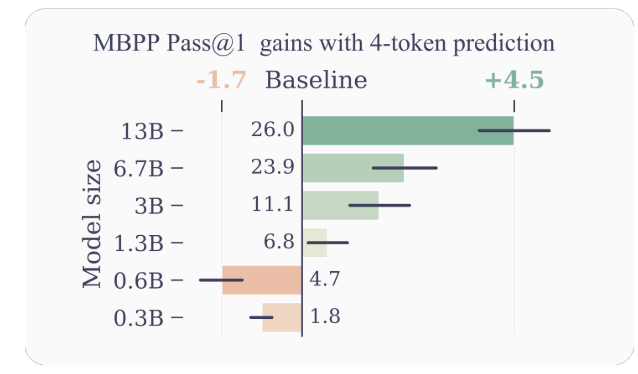
- Efficacité améliorée des échantillons: En encourageant le modèle à prédire plusieurs futurs jetons à la fois, la prédiction multi-jetons conduit le modèle vers une meilleure efficacité des échantillons. Les auteurs démontrent des améliorations significatives des performances sur les tâches de compréhension et de génération de code, avec des modèles comportant jusqu'à 13 B de paramètres résolvant environ 15 % de problèmes en plus en moyenne.
- Inférence plus rapide: Les têtes de sortie supplémentaires entraînées avec la prédiction multi-jetons peuvent être exploitées pour le décodage auto-spéculatif, une variante du décodage spéculatif qui permet une prédiction de jetons parallèle. Cela se traduit par des temps d'inférence jusqu'à 3 fois plus rapides sur une large gamme de tailles de lots, même pour les grands modèles.
- Promouvoir les dépendances à long terme: La prédiction multi-jetons encourage le modèle à capturer des dépendances et des modèles à plus long terme dans les données, ce qui est particulièrement bénéfique pour les tâches qui nécessitent une compréhension et un raisonnement sur des contextes plus larges.
- Raisonnement algorithmique: Les auteurs présentent des expériences sur des tâches synthétiques qui démontrent la supériorité des modèles de prédiction multi-jetons dans le développement de têtes d'induction et de capacités de raisonnement algorithmique, en particulier pour des modèles de plus petite taille.
- Cohérence et cohérence: En entraînant le modèle à prédire simultanément plusieurs futurs jetons, la prédiction multi-jetons encourage le développement de représentations cohérentes et cohérentes. Ceci est particulièrement utile pour les tâches qui nécessitent de générer un texte plus long et plus cohérent, comme la narration, l'écriture créative ou la génération de manuels pédagogiques.
- Généralisation amélioréeLes expériences des auteurs sur des tâches synthétiques suggèrent que les modèles de prédiction multi-jetons présentent de meilleures capacités de généralisation, notamment dans les contextes hors distribution. Cela est potentiellement dû à la capacité du modèle à capturer des modèles et des dépendances à plus long terme, ce qui peut l'aider à extrapoler plus efficacement à des scénarios inédits.

Exemples et intuitions
Pour donner plus d'intuition sur les raisons pour lesquelles la prédiction multi-jetons fonctionne si bien, considérons quelques exemples :
- Génération de code: Dans le contexte de la génération de code, la prédiction simultanée de plusieurs jetons peut aider le modèle à comprendre et à générer des structures de code plus complexes. Par exemple, lors de la génération d'une définition de fonction, prédire uniquement le jeton suivant peut ne pas fournir suffisamment de contexte pour que le modèle génère correctement l'intégralité de la signature de fonction. Cependant, en prédisant plusieurs jetons à la fois, le modèle peut mieux capturer les dépendances entre le nom de la fonction, les paramètres et le type de retour, conduisant ainsi à une génération de code plus précise et plus cohérente.
- Raisonnement en langage naturel: Considérons un scénario dans lequel un modèle de langage est chargé de répondre à une question qui nécessite un raisonnement sur plusieurs étapes ou informations. En prédisant plusieurs jetons simultanément, le modèle peut mieux capturer les dépendances entre les différentes composantes du processus de raisonnement, conduisant à des réponses plus cohérentes et précises.
- Génération de texte long: lors de la génération de texte long, tel que des histoires, des articles ou des rapports, le maintien de la cohérence et de l'homogénéité sur une période prolongée peut s'avérer difficile pour les modèles de langage entraînés avec la prédiction du jeton suivant. La prédiction multi-jetons encourage le modèle à développer des représentations qui capturent la structure et le flux global du texte, conduisant potentiellement à des générations longues plus cohérentes et cohérentes.
Limites et orientations futures
Bien que les résultats présentés dans le document soient impressionnants, il existe quelques limites et questions ouvertes qui méritent une enquête plus approfondie :
- Nombre optimal de jetons: L'article explore différentes valeurs de n (le nombre de futurs jetons à prédire) et constate que n=4 fonctionne bien pour de nombreuses tâches. Cependant, la valeur optimale de n peut dépendre de la tâche spécifique, de l'ensemble de données et de la taille du modèle. Le développement de méthodes fondées sur des principes pour déterminer le n optimal pourrait conduire à de nouvelles améliorations des performances.
- Taille du vocabulaire et tokenisation: Les auteurs notent que la taille optimale du vocabulaire et la stratégie de tokenisation pour les modèles de prédiction multi-jetons peuvent différer de celles utilisées pour les modèles de prédiction du prochain jeton. L'exploration de cet aspect pourrait conduire à de meilleurs compromis entre la longueur de la séquence compressée et l'efficacité du calcul.
- Pertes de prédiction auxiliaires: Les auteurs suggèrent que leurs travaux pourraient susciter l'intérêt pour le développement de nouvelles pertes de prédiction auxiliaire pour les grands modèles de langage, au-delà de la prédiction standard du prochain jeton. L’étude des pertes auxiliaires alternatives et de leurs combinaisons avec la prédiction multi-jetons est une direction de recherche passionnante.
- Compréhension théorique: Bien que l'article fournisse quelques intuitions et preuves empiriques de l'efficacité de la prédiction multi-jetons, une compréhension théorique plus approfondie du pourquoi et du comment cette approche fonctionne si bien serait précieuse.
Conclusion
Le document de recherche « Des modèles de langage étendus meilleurs et plus rapides via une prédiction multi-token » de Gloeckle et al. introduit un nouveau paradigme de formation susceptible d'améliorer considérablement les performances et les capacités des grands modèles de langage. En entraînant des modèles pour prédire simultanément plusieurs futurs jetons, la prédiction multi-jetons encourage le développement de dépendances à longue portée, de capacités de raisonnement algorithmique et d’une meilleure efficacité des échantillons.
La mise en œuvre technique proposée par les auteurs est élégante et efficace sur le plan informatique, ce qui permet d'appliquer cette approche à la formation de modèles de langage à grande échelle. De plus, la possibilité d’exploiter le décodage auto-spéculatif pour une inférence plus rapide constitue un avantage pratique significatif.
Bien qu’il reste encore des questions ouvertes et des domaines à explorer davantage, cette recherche représente une avancée passionnante dans le domaine des grands modèles de langage. Alors que la demande de modèles linguistiques plus performants et plus efficaces continue de croître, la prédiction multi-jetons pourrait devenir un élément clé de la prochaine génération de ces puissants systèmes d’IA.
J'ai passé les cinq dernières années à m'immerger dans le monde fascinant du Machine Learning et du Deep Learning. Ma passion et mon expertise m'ont amené à contribuer à plus de 50 projets de génie logiciel divers, avec un accent particulier sur l'IA/ML. Ma curiosité continue m'a également attiré vers le traitement automatique du langage naturel, un domaine que j'ai hâte d'explorer davantage.

Tu peux aimer
-


Suppression d'objets et de personnes dans une vidéo grâce à l'IA
-


Le codage intuitif souffre de l'expansion du rôle de l'IA
-


Le mur des GPU se fissure : la révolution invisible des architectures post-transformateurs
-


Google NotebookLM introduit une fonctionnalité de recherche approfondie
-


Yann LeCun, scientifique en chef spécialisé en IA chez Meta, envisage de quitter sa startup.
-


Comment faire passer des articles scientifiques absurdes devant les relecteurs IA











