Intelligence artificielle
SofGAN : Un générateur de visages basé sur GAN qui offre un contrôle accru
Des chercheurs de Shanghai et des États-Unis ont développé un système de génération de portraits basé sur GAN qui permet aux utilisateurs de créer des visages novateurs avec un niveau de contrôle sans précédent sur des aspects individuels tels que les cheveux, les yeux, les lunettes, les textures et la couleur.
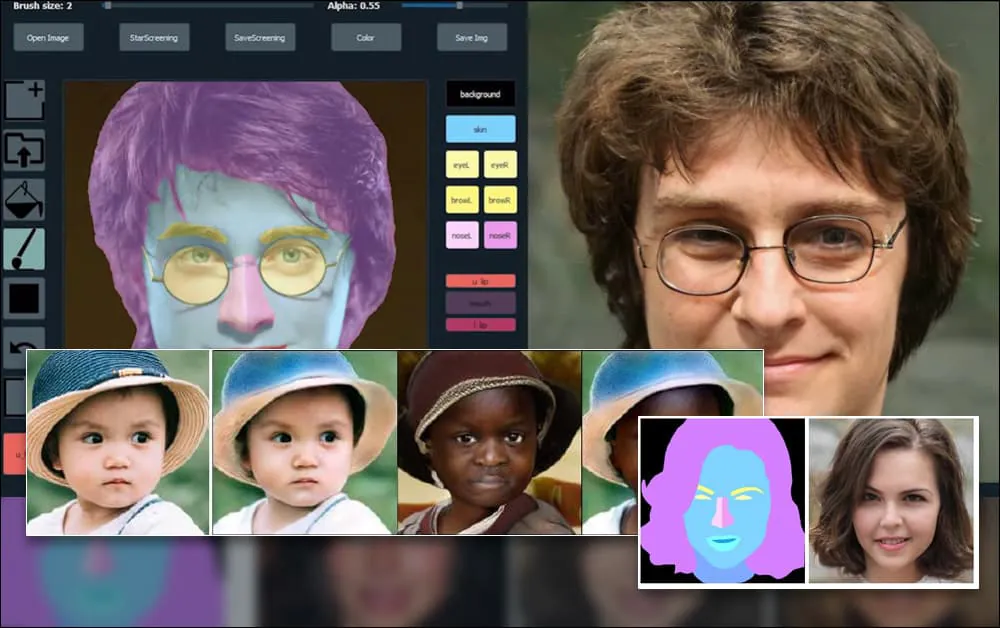
Pour démontrer la polyvalence du système, les créateurs ont fourni une interface de style Photoshop dans laquelle un utilisateur peut dessiner directement des éléments de segmentation sémantique qui seront réinterprétés en images réalistes, et qui peuvent même être obtenus en dessinant directement sur des photographies existantes.
Dans l’exemple ci-dessous, une photo de l’acteur Daniel Radcliffe est utilisée comme modèle de traçage (et l’objectif n’est pas de produire une ressemblance avec lui, mais plutôt une image photoréaliste générale). À mesure que l’utilisateur remplit les différents éléments, y compris des facettes discrètes telles que les lunettes, ils sont identifiés et interprétés dans l’image de dessin de sortie :
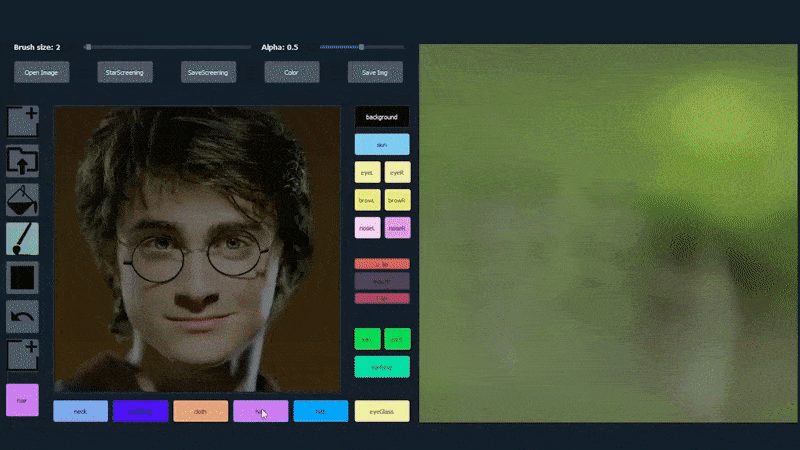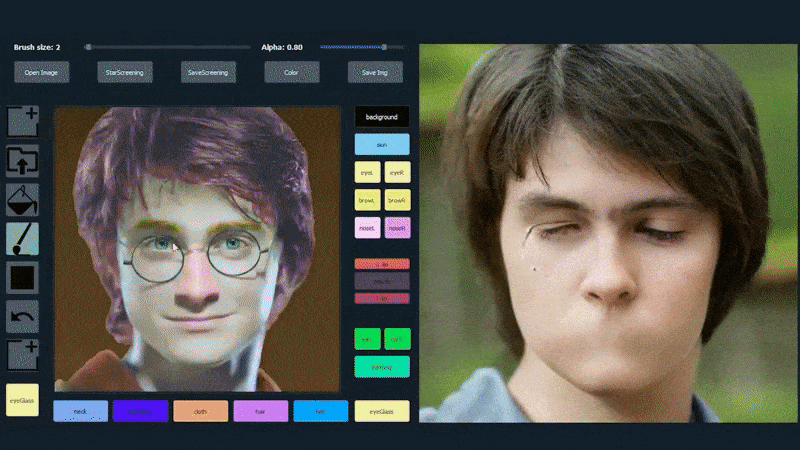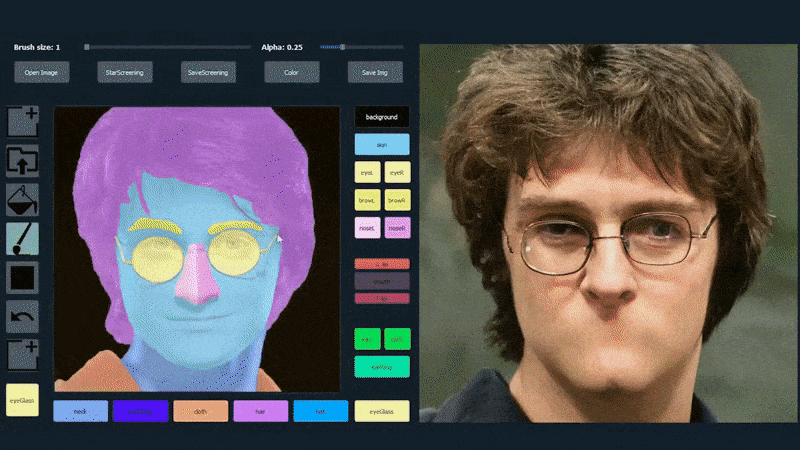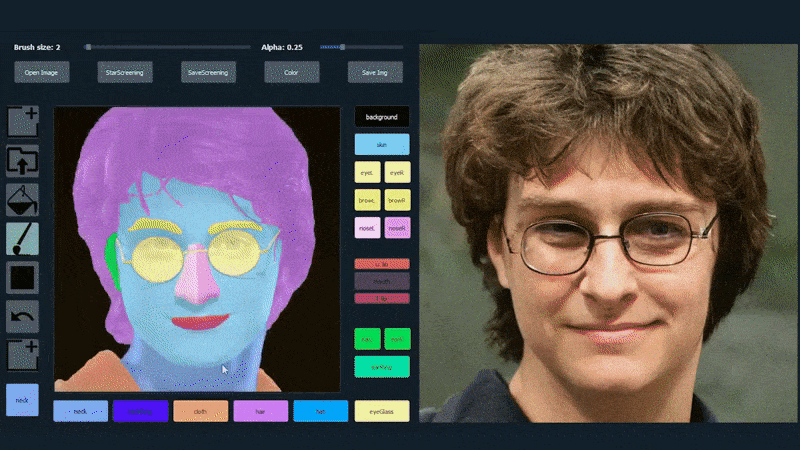
Utilisation d’une image comme matériau de traçage pour un portrait généré par SofGAN. Source: https://www.youtube.com/watch?v=xig8ZA3DVZ8
Le document s’intitule SofGAN: Un générateur d’images de portrait avec stylisation dynamique, et est dirigé par Anpei Chen et Ruiyang Liu, ainsi que deux autres chercheurs de l’Université de technologie de Shanghai et un autre de l’Université de Californie à San Diego.
Désentanglement des caractéristiques
La principale contribution de ce travail n’est pas tant de fournir une expérience utilisateur conviviale, mais plutôt de « désentangler » les caractéristiques des caractéristiques faciales apprises, telles que la pose et la texture, ce qui permet à SofGAN de générer également des visages qui sont à des angles indirects par rapport au point de vue de la caméra.

Insolite parmi les générateurs de visages basés sur les réseaux antagonistes génératifs, SofGAN peut changer l’angle de vue à volonté, dans les limites de la matrice d’angles présente dans les données d’entraînement. Source: https://arxiv.org/pdf/2007.03780.pdf
Puisque les textures sont maintenant désentanglement de la géométrie, la forme du visage et la texture peuvent également être manipulées comme des entités séparées. En effet, cela permet de changer la race d’un visage source, une pratique scandaleuse qui a maintenant une application potentiellement utile, pour la création de jeux de données d’apprentissage automatique équilibrés sur le plan racial.

SofGAN prend également en charge le vieillissement artificiel et l’ajustement de style cohérent avec les attributs à un niveau granulaire sans précédent dans les systèmes de segmentation vers image similaires, tels que GauGAN de NVIDIA et le système de rendu neuronal basé sur le jeu d’Intel system.

SofGAN est capable de mettre en œuvre le vieillissement comme un style itératif.
Une autre avancée de la méthodologie de SofGAN est que la formation ne nécessite pas d’images réelles appariées de segmentation, mais peut être formée directement sur des images réelles non appariées.
Les chercheurs déclarent que l’architecture de « désentanglement » de SofGAN a été inspirée par les systèmes de rendu d’images traditionnels, qui décomposent les éléments individuels d’une image. Dans les flux de travail d’effets visuels, les éléments d’un composite sont régulièrement décomposés en composants les plus minimes, avec des spécialistes dédiés à chaque composant.
Champ d’occupation sémantique (SOF)
Pour atteindre cet objectif dans un cadre de synthèse d’images par apprentissage automatique, les chercheurs ont développé un champ d’occupation sémantique (SOF), une extension du champ d’occupation traditionnel qui individualise les éléments constitutifs des portraits faciaux. Le SOF a été formé sur des cartes de segmentation sémantique multi-vues calibrées, mais sans aucune supervision de vérité de base.

Multiples itérations à partir d’une carte de segmentation unique (en bas à gauche).
En outre, des cartes de segmentation 2D sont obtenues en traçant les sorties du SOF, avant d’être texturées par un générateur GAN. Les cartes de segmentation sémantique « synthétiques » sont également codées dans un espace de dimension faible via un encodeur à trois couches pour assurer la continuité de la sortie lorsque le point de vue est modifié.
Le schéma de formation mélange spatialement deux styles aléatoires pour chaque région sémantique :

L’architecture pour SofGAN.
Les chercheurs affirment que SofGAN atteint une distance de Fréchet Inception (FID) inférieure à celle des approches actuelles de l’état de l’art (SOTA), ainsi qu’un métrique de similarité d’images apprises par patch (LPIPS) plus élevée.
Les approches StyleGAN précédentes ont souvent été entravées par l’entanglement de fonctionnalités, dans lequel les éléments qui composent une image sont irrémédiablement liés les uns aux autres, provoquant l’apparition d’éléments indésirables aux côtés d’un élément souhaité (par exemple, des boucles d’oreilles peuvent apparaître lorsqu’une forme d’oreille est rendue qui a été informée au moment de la formation par une image qui présentait des boucles d’oreilles).

Traçage des rayons est utilisé pour calculer le volume des cartes de segmentation sémantique, permettant plusieurs points de vue.
Jeux de données et formation
Trois jeux de données ont été utilisés dans le développement de diverses implémentations de SofGAN : CelebAMask-HQ, un référentiel de 30 000 images haute résolution issues du jeu de données CelebA-HQ ; Flickr-Faces-HQ de NVIDIA (FFHQ), qui contient 70 000 images, où les chercheurs ont étiqueté les images avec un analyseur de visage pré-entraîné ; et un groupe auto-produit de 122 scans de portraits avec des régions sémantiques étiquetées manuellement.
Le SOF est composé de trois sous-modules entraînables – le hyper-réseau, un marcheur de rayons (voir image ci-dessus) et un classificateur. Le générateur de style de l’instance sémantique (SIW) du projet est configuré de manière similaire à StyleGAN2 dans certains aspects. L’augmentation de données est appliquée via un scaling et un recadrage aléatoires, et la formation comporte une régularisation de chemin tous les quatre pas. La procédure d’entraînement complète a pris 22 jours pour atteindre 800 000 itérations sur quatre GPU RTX 2080 Ti sur CUDA 10.1.
Le document ne mentionne pas la configuration des cartes 2080, qui peuvent accueillir entre 11 Go et 22 Go de VRAM chacune, ce qui signifie que la VRAM totale employée pendant la majeure partie du mois pour former SofGAN se situe entre 44 Go et 88 Go.
Les chercheurs observent que des résultats généralisés et de haute qualité ont commencé à émerger tôt dans la formation, à 1500 itérations, trois jours après le début de la formation. Le reste de la formation a été consacré à la progression lente vers l’obtention de détails fins tels que les cheveux et les facettes des yeux.
SofGAN atteint généralement des résultats plus réalistes à partir d’une seule carte de segmentation que les méthodes rivales telles que SPADE de NIVDIA et Pix2PixHD, et SEAN.

Ci-dessous se trouve la vidéo publiée par les chercheurs. D’autres vidéos auto-hébergées sont disponibles sur la page du projet.












