Intelligence artificielle
Révolutionner les soins de santé : explorer l’impact et l’avenir des grands modèles de langage en médecine

L’intégration et l’application de grands modèles de langage (LLM) en médecine et dans les soins de santé ont été un sujet d’intérêt et de développement significatifs.
Comme noté dans la conférence mondiale de la Healthcare Information Management and Systems Society et d’autres événements notables, des entreprises comme Google sont à la tête de l’exploration du potentiel de l’IA générative dans les soins de santé. Leurs initiatives, telles que Med-PaLM 2, mettent en évidence l’évolution du paysage des solutions de soins de santé basées sur l’IA, en particulier dans des domaines tels que le diagnostic, les soins aux patients et l’efficacité administrative.
Le Med-PaLM 2 de Google, un LLM pionnier dans le domaine des soins de santé, a démontré des capacités impressionnantes, notamment en atteignant un niveau “expert” dans les questions de style d’examen de licence médicale américaine. Ce modèle, et d’autres similaires, promettent de révolutionner la façon dont les professionnels de la santé accèdent et utilisent les informations, améliorant potentiellement la précision du diagnostic et l’efficacité des soins aux patients.
Cependant, aux côtés de ces progrès, des inquiétudes concernant la praticité et la sécurité de ces technologies dans les contextes cliniques ont été soulevées. Par exemple, la dépendance à l’égard de vastes sources de données Internet pour la formation de modèles, bien que bénéfique dans certains contextes, n’est pas toujours appropriée ou fiable pour les fins médicales. Comme le souligne Nigam Shah, PhD, MBBS, chef des données scientifiques pour Stanford Health Care, les questions cruciales à poser concernent les performances de ces modèles dans les contextes médicaux réels et leur impact réel sur les soins aux patients et l’efficacité des soins de santé.
La perspective du Dr Shah souligne la nécessité d’une approche plus ciblée pour utiliser les LLM dans la médecine. Au lieu de modèles à usage général formés sur des données Internet larges, il suggère une stratégie plus focalisée où les modèles sont formés sur des données médicales spécifiques et pertinentes. Cette approche ressemble à la formation d’un internat en médecine – en leur fournissant des tâches spécifiques, en supervisant leurs performances et en leur permettant progressivement plus d’autonomie à mesure qu’ils démontrent leur compétence.
Dans le même esprit, le développement de Meditron par les chercheurs de l’EPFL présente une avancée intéressante dans le domaine. Meditron, un LLM open-source spécifiquement conçu pour les applications médicales, représente un progrès significatif. Formé sur des données médicales ciblées provenant de sources réputées comme PubMed et des lignes directrices cliniques, Meditron offre un outil plus ciblé et potentiellement plus fiable pour les praticiens médicaux. Sa nature open-source non seulement promeut la transparence et la collaboration, mais permet également une amélioration continue et des tests de résistance par la communauté de recherche plus large.

MEDITRON-70B-achieves-an-accuracy-of-70.2-on-USMLE-style-questions-in-the-MedQA-4-options-dataset
Le développement d’outils comme Meditron, Med-PaLM 2 et d’autres reflète une reconnaissance croissante des exigences uniques du secteur des soins de santé en ce qui concerne les applications de l’IA. L’accent mis sur la formation de ces modèles sur des données médicales pertinentes et de haute qualité, et sur la garantie de leur sécurité et de leur fiabilité dans les contextes cliniques, est très crucial.
De plus, l’inclusion de jeux de données diversifiés, tels que ceux provenant de contextes humanitaires comme le Comité international de la Croix-Rouge, démontre une sensibilité aux besoins et aux défis variés dans les soins de santé mondiaux. Cette approche s’aligne sur la mission plus large de nombreux centres de recherche en IA, qui visent à créer des outils d’IA qui ne sont pas seulement techniquement avancés, mais également socialement responsables et bénéfiques.
L’article intitulé “Les grands modèles de langage encodent les connaissances cliniques” récemment publié dans Nature, explore comment les grands modèles de langage (LLM) peuvent être efficacement utilisés dans les contextes cliniques. La recherche présente des connaissances et des méthodologies révolutionnaires, éclairant les capacités et les limites des LLM dans le domaine médical.
Le domaine médical se caractérise par sa complexité, avec une vaste gamme de symptômes, de maladies et de traitements qui évoluent constamment. Les LLM doivent non seulement comprendre cette complexité, mais également suivre les dernières connaissances et lignes directrices médicales.
Le cœur de cette recherche tourne autour d’un nouveau référentiel appelé MultiMedQA. Ce référentiel combine six jeux de données de questions-réponses médicales existants avec un nouveau jeu de données, HealthSearchQA, qui comprend des questions médicales fréquemment recherchées en ligne. Cette approche globale vise à évaluer les LLM sur diverses dimensions, notamment la factualité, la compréhension, le raisonnement, les dommages possibles et les préjugés, abordant ainsi les limites des évaluations automatisées précédentes qui reposaient sur des référentiels limités.
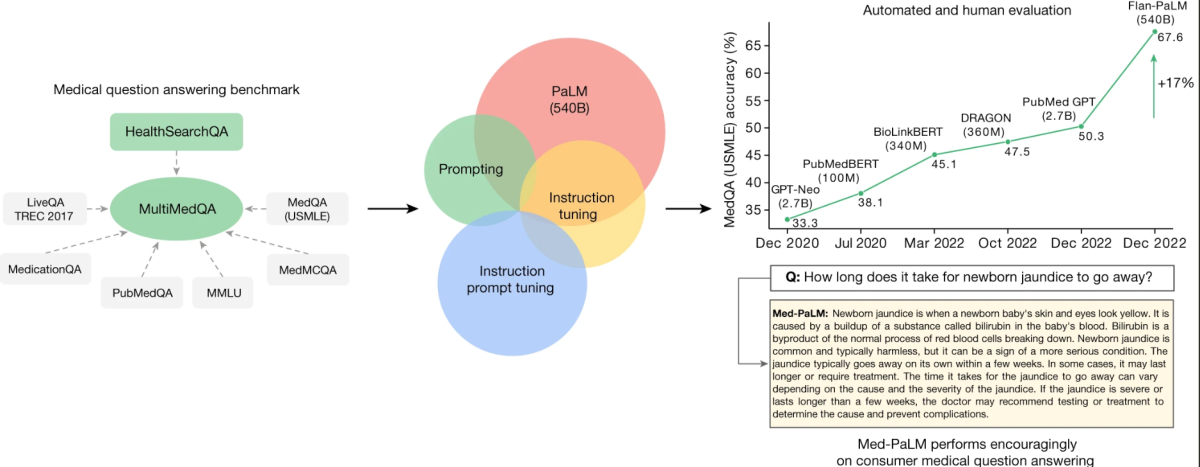
MultiMedQA, un référentiel pour répondre aux questions médicales couvrant l’examen médical
La clé de l’étude est l’évaluation du modèle de langage Pathways (PaLM), un LLM de 540 milliards de paramètres, et de sa variante à instruction, Flan-PaLM, sur MultiMedQA. De manière remarquable, Flan-PaLM atteint une précision de pointe sur tous les jeux de données à choix multiple au sein de MultiMedQA, y compris une précision de 67,6 % sur MedQA, qui comprend des questions de style d’examen de licence médicale américaine. Cette performance marque une amélioration significative par rapport aux modèles précédents, dépassant l’état de l’art précédent de plus de 17 %.
MedQA
Le jeu de données MedQA3 présente des questions stylisées après l’examen de licence médicale américaine, chacune avec quatre ou cinq options de réponses. Il comprend un ensemble de développement avec 11 450 questions et un ensemble de test comprenant 1 273 questions.
Format : question et réponse (Q + A), multiple choix, domaine ouvert.
Exemple de question : Un homme de 65 ans souffrant d'hypertension se présente chez le médecin pour un examen de santé de routine. Les médicaments actuels incluent l'aténolol, le lisinopril et l'atorvastatine. Son pouls est de 86 min-1, les respirations sont de 18 min-1 et la pression artérielle est de 145/95 mmHg. L'examen cardiaque révèle un murmure diastolique. Quel est le facteur le plus probable à l'origine de cet examen physique ?
Réponses (réponse correcte en gras) : (A) Diminution de la compliance du ventricule gauche, (B) Dégradation myxomateuse de la valve mitrale (C) Inflammation du péricarde (D) Dilatation de la racine aortique (E) Épaississement des feuilles de la valve mitrale.
L’étude identifie également des lacunes critiques dans les performances du modèle, en particulier dans la réponse aux questions médicales des consommateurs. Pour répondre à ces problèmes, les chercheurs introduisent une méthode appelée ajustement d’instruction. Cette technique aligne efficacement les LLM sur de nouveaux domaines à l’aide de quelques exemples, aboutissant à la création de Med-PaLM. Le modèle Med-PaLM, bien qu’il se comporte de manière encourageante et montre une amélioration dans la compréhension, la mémorisation des connaissances et le raisonnement, reste encore en deçà par rapport aux cliniciens.
Un aspect notable de cette recherche est le cadre d’évaluation humaine détaillé. Ce cadre évalue les réponses des modèles pour leur accord avec le consensus scientifique et les résultats potentiellement nocifs. Par exemple, alors que seulement 61,9 % des réponses longues de Flan-PaLM correspondent au consensus scientifique, ce chiffre augmente à 92,6 % pour Med-PaLM, comparable aux réponses générées par les cliniciens. De même, le potentiel de résultats nocifs a été considérablement réduit dans les réponses de Med-PaLM par rapport à Flan-PaLM.
L’évaluation humaine des réponses de Med-PaLM a mis en évidence sa compétence dans plusieurs domaines, s’alignant étroitement sur les réponses générées par les cliniciens. Cela souligne le potentiel de Med-PaLM en tant qu’outil de soutien dans les contextes cliniques.
La recherche discutée ci-dessus explore les complexités de l’amélioration des grands modèles de langage (LLM) pour les applications médicales. Les techniques et les observations de cette étude peuvent être généralisées pour améliorer les capacités des LLM dans divers domaines. Explorons ces aspects clés :
Ajustement d’instruction améliore les performances
- Application généralisée : L’ajustement d’instruction, qui consiste à affiner les LLM avec des instructions ou des lignes directrices spécifiques, a montré une amélioration significative des performances dans divers domaines. Cette technique pourrait être appliquée à d’autres domaines tels que les domaines juridiques, financiers ou éducatifs pour améliorer la précision et la pertinence des sorties des LLM.
Augmentation de la taille du modèle
- Implications plus larges : L’observation selon laquelle l’augmentation de la taille du modèle améliore les performances n’est pas limitée à la réponse aux questions médicales. Les modèles plus grands, avec plus de paramètres, ont la capacité de traiter et de générer des réponses plus nuancées et complexes. Cette mise à l’échelle peut être bénéfique dans des domaines tels que le service client, la rédaction créative ou le support technique, où une compréhension et une génération de réponses nuancées sont cruciales.
Chaîne de pensée (COT) pour l’invocation
- Utilisation dans des domaines divers : L’utilisation de la chaîne de pensée (COT), bien qu’elle n’améliore pas toujours les performances dans les jeux de données médicaux, peut être précieuse dans d’autres domaines où la résolution de problèmes complexes est requise. Par exemple, dans la dépannage technique ou la prise de décision complexe, la chaîne de pensée peut guider les LLM pour traiter l’information étape par étape, conduisant à des sorties plus précises et raisonnées.
Cohérence interne pour une précision améliorée
- Applications plus larges : La technique de cohérence interne, où plusieurs sorties sont générées et la réponse la plus cohérente est sélectionnée, peut considérablement améliorer les performances dans divers domaines. Dans des domaines tels que la finance ou le droit, où la précision est primordiale, cette méthode peut être utilisée pour vérifier les sorties générées pour une fiabilité plus élevée.
Incertitude et prédiction sélective
- Pertinence interdomaine : La communication des estimations d’incertitude est cruciale dans des domaines où les informations erronées peuvent avoir des conséquences graves, comme les soins de santé et le droit. Utiliser la capacité des LLM à exprimer l’incertitude et à différer sélectivement les prédictions lorsqu’ils ont une faible confiance peut être un outil crucial dans ces domaines pour prévenir la diffusion d’informations inexactes.
L’application dans le monde réel de ces modèles s’étend au-delà de la réponse aux questions. Ils peuvent être utilisés pour l’éducation des patients, l’aide au processus de diagnostic et même dans la formation des étudiants en médecine. Cependant, leur déploiement doit être soigneusement géré pour éviter de s’appuyer sur l’IA sans une surveillance humaine appropriée.
À mesure que les connaissances médicales évoluent, les LLM doivent également s’adapter et apprendre. Cela nécessite des mécanismes d’apprentissage et de mise à jour continus, garantissant que les modèles restent pertinents et précis avec le temps.












