Intelligence artificielle
DALL-E 2 n’est-il qu’un outil de collage d’éléments sans compréhension de leurs relations ?

Un nouveau document de recherche de l’Université de Harvard suggère que le cadre de génération d’images texte-à-image DALL-E 2 d’OpenAI, qui a fait les gros titres, a des difficultés notables à reproduire même les relations au niveau des nourrissons entre les éléments qu’il compose dans les photos synthétisées, malgré la sophistication éblouissante de beaucoup de ses sorties.
Les chercheurs ont mené une étude auprès des utilisateurs impliquant 169 participants recrutés par crowdsourcing, qui ont été présentés avec des images DALL-E 2 basées sur les principes humains les plus basiques de sémantique de relation, ainsi que les textes-prompts qui les avaient créés. Lorsqu’on leur a demandé si les prompts et les images étaient liés, moins de 22 % des images ont été perçues comme pertinentes par rapport à leurs prompts associés, en termes de relations très simples que DALL-E 2 était censé visualiser.

Une capture d’écran des essais menés pour le nouveau document. Les participants ont été chargés de sélectionner toutes les images qui correspondaient au prompt. Malgré l’avertissement en bas de l’interface, dans tous les cas, les images, inconnues des participants, étaient en fait générées à partir du prompt associé affiché. Source : https://arxiv.org/pdf/2208.00005.pdf
Les résultats suggèrent également que l’apparente capacité de DALL-E à conjoindre des éléments disparates peut diminuer à mesure que ces éléments deviennent moins susceptibles d’avoir été présents dans les données d’entraînement réelles qui alimentent le système.
Par exemple, les images pour le prompt « un enfant touchant un bol » ont obtenu un taux d’accord de 87 % (c’est-à-dire que les participants ont cliqué sur la plupart des images comme étant pertinentes par rapport au prompt), tandis que des rendus photoréalistes similaires de « un singe touchant un iguane » n’ont obtenu qu’un taux d’accord de 11 % :


DALL-E a du mal à dépeindre l’événement peu probable d’un ‘singe touchant un iguane’, probablement parce qu’il est peu commun, voire inexistant, dans l’ensemble d’entraînement.
Dans le deuxième exemple, DALL-E 2 se trompe fréquemment sur l’échelle et même sur l’espèce, probablement en raison d’un manque d’images réelles qui dépeignent cet événement. En revanche, il est raisonnable de s’attendre à un grand nombre de photos d’entraînement liées aux enfants et à la nourriture, et que ce sous-domaine/classe est bien développé.
La difficulté de DALL-E à juxtaposer des éléments d’image fortement contrastés suggère que le public est actuellement si ébloui par les capacités photoréalistes et interprétatives du système qu’il n’a pas développé d’œil critique pour les cas où le système a effectivement simplement « collé » un élément de manière frappante sur un autre, comme dans ces exemples du site officiel de DALL-E 2 :

Synthèse de collage, à partir des exemples officiels pour DALL-E 2. Source : https://openai.com/dall-e-2/
Le nouveau document indique* :
‘La compréhension relationnelle est un composant fondamental de l’intelligence humaine, qui se manifeste tôt dans le développement, et est calculée rapidement et automatiquement dans la perception.
‘La difficulté de DALL-E 2 avec même les relations spatiales de base (comme in, on, under) suggère que ce qu’il a appris, il n’a pas encore appris les types de représentations qui permettent aux humains de structurer ainsi la monde de manière si flexible et robuste.
‘Une interprétation directe de cette difficulté est que des systèmes comme DALL-E 2 n’ont pas encore de compositionnalité relationnelle.’
Les auteurs suggèrent que les systèmes de génération d’images guidés par du texte, tels que la série DALL-E, pourraient bénéficier de l’utilisation d’algorithmes courants en robotique, qui modélisent les identités et les relations simultanément, en raison de la nécessité pour l’agent d’interagir réellement avec l’environnement plutôt que de simplement fabriquer un mélange d’éléments divers.
Une telle approche, intitulée CLIPort, utilise le même mécanisme CLIP qui sert d’élément d’évaluation de la qualité dans DALL-E 2 :
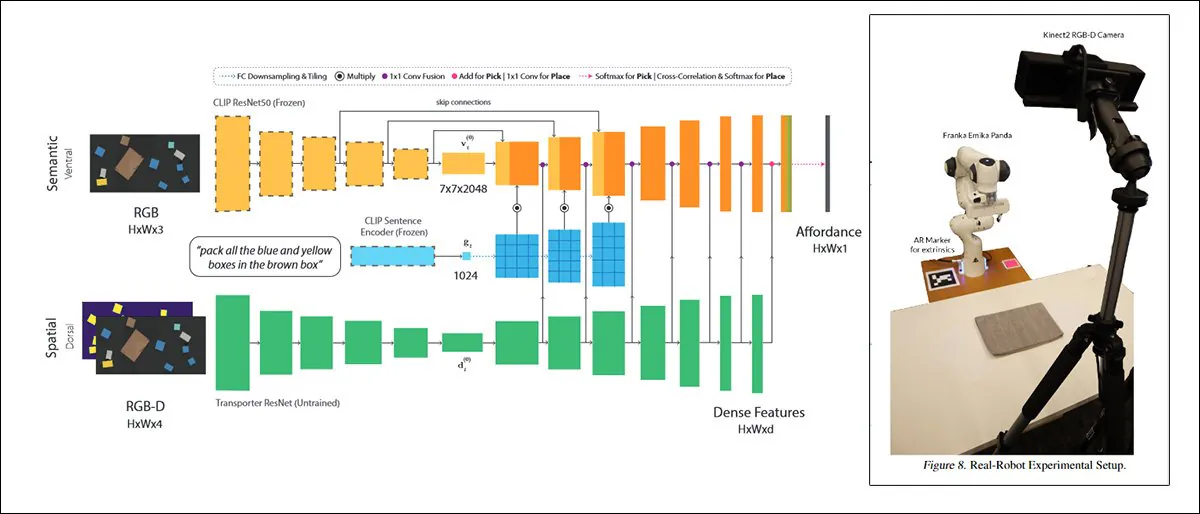
CLIPort, une collaboration de 2021 entre l’Université de Washington et NVIDIA, utilise CLIP dans un contexte si pratique que les systèmes formés sur celui-ci doivent nécessairement développer une compréhension des relations physiques, un facteur de motivation qui est absent dans DALL-E 2 et des cadres de synthèse d’images similaires ‘fantastiques’. Source : https://arxiv.org/pdf/2109.12098.pdf
Les auteurs suggèrent en outre qu’une autre amélioration possible pourrait être que l’architecture des systèmes de synthèse d’images, tels que DALL-E, incorpore des effets multiplicatifs dans une seule couche de calcul, permettant le calcul des relations d’une manière inspirée des capacités de traitement de l’information des systèmes biologiques biologiques.
Le nouveau document est intitulé Testing Relational Understanding in Text-Guided Image Generation, et provient de Colin Conwell et Tomer D. Ullman du département de psychologie de Harvard.
Au-delà des critiques précoces
En commentant le « tour de passe-passe » derrière le réalisme et l’intégrité de la sortie de DALL-E 2, les auteurs notent des travaux antérieurs qui ont trouvé des lacunes dans les systèmes de génération d’images de type DALL-E.
En juin de cette année, l’UoC Berkeley a noté la difficulté que DALL-E a à gérer les réflexions et les ombres ; le même mois, une étude de Corée a examiné l’« unicité » et l’originalité de la sortie de type DALL-E 2 avec un œil critique ; une analyse préliminaire des images DALL-E 2, peu après son lancement, de NYU et de l’Université du Texas, a trouvé divers problèmes avec la compositionnalité et d’autres facteurs essentiels dans les images DALL-E 2 ; et le mois dernier, un travail conjoint entre l’Université de l’Illinois et MIT a proposé des suggestions pour améliorer l’architecture de tels systèmes en termes de compositionnalité.
Les chercheurs notent en outre que des personnalités de DALL-E telles qu’Aditya Ramesh ont reconnu les problèmes du cadre avec le lien, la taille relative, le texte et d’autres défis.
Les développeurs derrière le système de synthèse d’images rival de Google, Imagen, ont également proposé DrawBench, un système de comparaison novateur qui évalue la précision des images à travers les cadres avec des métriques diverses.
Au lieu de cela, les auteurs du nouveau document suggèrent qu’un meilleur résultat pourrait être obtenu en opposant l’estimation humaine – plutôt que des métriques algorithmiques internes – aux images résultantes, pour établir où se trouvent les faiblesses et ce qui pourrait être fait pour les atténuer.
L’étude
À cette fin, le nouveau projet base son approche sur des principes psychologiques et cherche à se retirer de l’actuel essor d’intérêt pour l’ingénierie de prompt (qui est, en effet, une concession aux lacunes de DALL-E 2, ou de tout système comparable), pour examiner et potentiellement résoudre les limites qui rendent de telles « solutions » nécessaires.












