Intelligence artificielle
Comment fonctionne la génération 3D à partir de texte AI : Meta 3D Gen, OpenAI Shap-E et plus
By
Aayush Mittal Mittal
La capacité de générer des actifs numériques 3D à partir de texte représente l’un des développements les plus passionnants récemment dans l’IA et l’informatique graphique. Alors que le marché des actifs numériques 3D devrait passer de $28,3 milliards en 2024 à 51,8 milliards d’ici 2029, les modèles de texte-3D sont prêts à jouer un rôle majeur dans la révolution de la création de contenu dans des secteurs tels que les jeux, le cinéma, l’e-commerce et plus. Mais comment fonctionnent exactement ces systèmes d’IA ? Dans cet article, nous allons plonger dans les détails techniques derrière la génération de texte-3D.

Le défi de la génération 3D
Générer des actifs 3D à partir de texte est une tâche beaucoup plus complexe que la génération d’images 2D. Alors que les images 2D sont essentiellement des grilles de pixels, les actifs 3D nécessitent de représenter la géométrie, les textures, les matériaux et souvent les animations dans l’espace 3D. Cette dimension supplémentaire et complexité rendent la tâche de génération beaucoup plus difficile.
Certains défis clés dans la génération de texte-3D incluent :
- Représenter la géométrie et la structure 3D
- Générer des textures et des matériaux cohérents sur la surface 3D
- Assurer la plausibilité physique et la cohérence de plusieurs points de vue
- Capturer les détails fins et la structure globale simultanément
- Générer des actifs qui peuvent être facilement rendus ou imprimés en 3D
Pour relever ces défis, les modèles de texte-3D utilisent plusieurs technologies et techniques clés.
Composants clés des systèmes de texte-3D
La plupart des systèmes de génération de texte-3D de pointe partagent quelques composants de base :
- Encodage de texte : Convertir le texte d’entrée en une représentation numérique
- Représentation 3D : Une méthode pour représenter la géométrie et l’apparence 3D
- Modèle génératif : Le modèle d’IA principal pour générer l’actif 3D
- Rendering : Convertir la représentation 3D en images 2D pour la visualisation
Explorons chacun de ces éléments en détail.
Encodage de texte
La première étape consiste à convertir le texte d’entrée en une représentation numérique que le modèle d’IA peut utiliser. Cela est généralement réalisé à l’aide de grands modèles de langage comme BERT ou GPT.
Représentation 3D
Il existe plusieurs façons courantes de représenter la géométrie 3D dans les modèles d’IA :
- Grilles de voxels : Tableaux 3D de valeurs représentant l’occupation ou les fonctionnalités
- Nuages de points : Ensembles de points 3D
- Maillages : Sommets et faces définissant une surface
- Fonctions implicites : Fonctions continues définissant une surface (par exemple, fonctions de distance signée)
- Champs de rayonnement neuronaux (NeRFs) : Réseaux de neurones représentant la densité et la couleur dans l’espace 3D
Chacun présente des compromis en termes de résolution, d’utilisation de la mémoire et de facilité de génération. De nombreux modèles récents utilisent des fonctions implicites ou des NeRF, car ils permettent d’obtenir des résultats de haute qualité avec des exigences computationally raisonnables.
Par exemple, nous pouvons représenter une sphère simple comme une fonction de distance signée :
import numpy as np
def sphere_sdf(x, y, z, radius=1.0):
return np.sqrt(x**2 + y**2 + z**2) - radius
# Évaluer la SDF à un point 3D
point = [0.5, 0.5, 0.5]
distance = sphere_sdf(*point)
print(f"Distance à la surface de la sphère : {distance}")
Modèle génératif
Le cœur d’un système de texte-3D est le modèle génératif qui produit la représentation 3D à partir de l’intégration de texte. La plupart des modèles de pointe utilisent une variation d’un modèle de diffusion, similaire à ceux utilisés dans la génération d’images 2D.
Les modèles de diffusion fonctionnent en ajoutant progressivement du bruit aux données, puis en apprenant à inverser ce processus. Pour la génération 3D, ce processus se déroule dans l’espace de la représentation 3D choisie.
Un pseudocode simplifié pour une étape d’entraînement d’un modèle de diffusion pourrait ressembler à :
def diffusion_training_step(model, x_0, text_embedding): # Échantillonnez une étape de temps aléatoire t = torch.randint(0, num_timesteps, (1,)) # Ajoutez du bruit à l'entrée noise = torch.randn_like(x_0) x_t = add_noise(x_0, noise, t) # Prédisez le bruit predicted_noise = model(x_t, t, text_embedding) # Calculez la perte loss = F.mse_loss(noise, predicted_noise) return loss # Boucle d'entraînement for batch in dataloader: x_0, text = batch text_embedding = encode_text(text) loss = diffusion_training_step(model, x_0, text_embedding) loss.backward() optimizer.step()
Pendant la génération, nous partons d’un bruit pur et débruitons itérativement, conditionnés par l’intégration de texte.
Rendering
Pour visualiser les résultats et calculer les pertes pendant l’entraînement, nous devons rendre notre représentation 3D en images 2D. Cela est généralement réalisé à l’aide de techniques de rendu différentiable qui permettent aux gradients de s’écouler à rebours dans le processus de rendu.
Pour les représentations basées sur des maillages, nous pourrions utiliser un rendu basé sur la rasterisation :
import torch import torch.nn.functional as F import pytorch3d.renderer as pr def render_mesh(vertices, faces, image_size=256): # Créez un rendu renderer = pr.MeshRenderer( rasterizer=pr.MeshRasterizer(), shader=pr.SoftPhongShader() ) # Configurez la caméra cameras = pr.FoVPerspectiveCameras() # Rendez images = renderer(vertices, faces, cameras=cameras) return images # Exemple d'utilisation vertices = torch.rand(1, 100, 3) # Sommets aléatoires faces = torch.randint(0, 100, (1, 200, 3)) # Faces aléatoires rendered_images = render_mesh(vertices, faces)
Pour les représentations implicites comme les NeRF, nous utilisons généralement des techniques de marche de rayon pour rendre les vues.
Ensemble : Le pipeline de texte-3D
Maintenant que nous avons couvert les composants clés, explorons comment ils se combinent dans un pipeline de génération de texte-3D typique :
- Encodage de texte : Le texte d’entrée est encodé en une représentation vectorielle dense à l’aide d’un modèle de langage.
- Génération initiale : Un modèle de diffusion, conditionné par l’intégration de texte, génère une représentation 3D initiale (par exemple, un NeRF ou une fonction implicite).
- Cohérence multi-vue : Le modèle rend plusieurs vues de l’actif 3D généré et assure la cohérence entre les points de vue.
- Affinement : Des réseaux supplémentaires peuvent affiner la géométrie, ajouter des textures ou améliorer les détails.
- Sortie finale : La représentation 3D est convertie en un format souhaité (par exemple, un maillage texturé) pour une utilisation dans des applications en aval.
Voici un exemple simplifié de ce à quoi cela pourrait ressembler en code :
class TextTo3D(nn.Module):
def __init__(self):
super().__init__()
self.text_encoder = BertModel.from_pretrained('bert-base-uncased')
self.diffusion_model = DiffusionModel()
self.refiner = RefinerNetwork()
self.renderer = DifferentiableRenderer()
def forward(self, text_prompt):
# Encode le texte
text_embedding = self.text_encoder(text_prompt).last_hidden_state.mean(dim=1)
# Générez la représentation 3D initiale
initial_3d = self.diffusion_model(text_embedding)
# Rendez plusieurs vues
views = self.renderer(initial_3d, num_views=4)
# Affinez en fonction de la cohérence multi-vue
refined_3d = self.refiner(initial_3d, views)
return refined_3d
# Utilisation
model = TextTo3D()
text_prompt = "Une voiture de sport rouge"
generated_3d = model(text_prompt)
Meilleurs modèles d’actifs 3D disponibles
3DGen – Meta
3DGen est conçu pour résoudre le problème de la génération de contenu 3D – tel que des personnages, des accessoires et des scènes – à partir de descriptions textuelles.
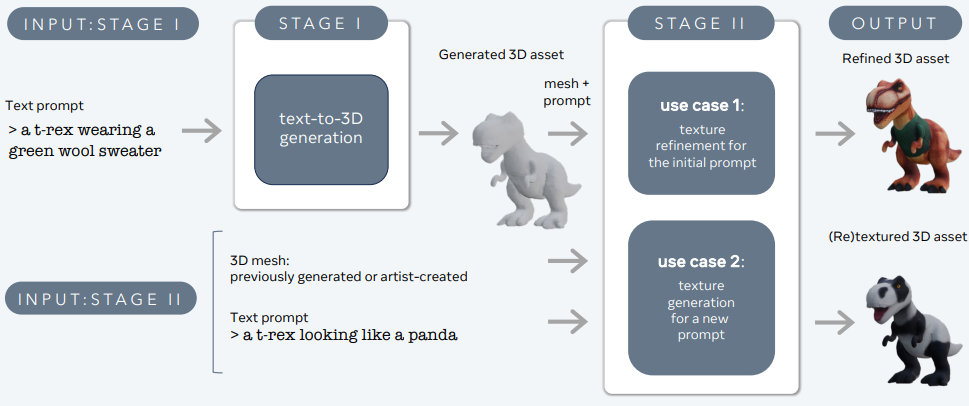
Large Language and Text-to-3D Models – 3d-gen
3DGen prend en charge le rendu basé sur la physique (PBR), essentiel pour la reluminisation réaliste des actifs 3D dans les applications du monde réel. Il permet également la retexturisation générative de formes 3D générées ou créées par des artistes à l’aide de nouvelles entrées textuelles. Le pipeline intègre deux composants principaux : Meta 3D AssetGen et Meta 3D TextureGen, qui gèrent respectivement la génération de texte-3D et de texte-texture.
Meta 3D AssetGen
Meta 3D AssetGen (Siddiqui et al., 2024) est responsable de la génération initiale d’actifs 3D à partir de texte. Ce composant produit un maillage 3D avec des textures et des cartes de matériaux PBR en environ 30 secondes.
Meta 3D TextureGen
Meta 3D TextureGen (Bensadoun et al., 2024) affine les textures générées par AssetGen. Il peut également être utilisé pour générer de nouvelles textures pour des maillages 3D existants en fonction de descriptions textuelles supplémentaires. Cette étape prend environ 20 secondes.
Point-E (OpenAI)
Point-E, développé par OpenAI, est un autre modèle de génération de texte-3D notable. Contrairement à DreamFusion, qui produit des représentations NeRF, Point-E génère des nuages de points 3D.
Caractéristiques clés de Point-E :
a) Pipeline à deux étapes : Point-E génère d’abord une vue synthétique 2D à l’aide d’un modèle de diffusion de texte-à-image, puis utilise cette image pour conditionner un deuxième modèle de diffusion qui produit le nuage de points 3D.
b) Efficacité : Point-E est conçu pour être efficace sur le plan computationnel, capable de générer des nuages de points 3D en quelques secondes sur une seule GPU.
c) Informations de couleur : Le modèle peut générer des nuages de points colorés, préservant à la fois les informations géométriques et d’apparence.
Limitations :
- Fidélité inférieure par rapport aux approches basées sur des maillages ou des NeRF
- Les nuages de points nécessitent un traitement supplémentaire pour de nombreuses applications en aval
Shap-E (OpenAI) :
En s’appuyant sur Point-E, OpenAI a introduit Shap-E, qui génère des maillages 3D au lieu de nuages de points. Cela répond à certaines des limites de Point-E tout en maintenant l’efficacité computationnelle.
Caractéristiques clés de Shap-E :
a) Représentation implicite : Shap-E apprend à générer des représentations implicites (fonctions de distance signée) d’objets 3D.
b) Extraction de maillage : Le modèle utilise une mise en œuvre différentiable de l’algorithme de marches de cubes pour convertir la représentation implicite en un maillage polygonal.
c) Génération de texture : Shap-E peut également générer des textures pour les maillages 3D, aboutissant à des sorties visuellement plus attrayantes.
Avantages :
- Temps de génération rapides (secondes à minutes)
- Sortie de maillage directe adaptée au rendu et aux applications en aval
- Capacité à générer à la fois la géométrie et la texture
GET3D (NVIDIA) :
GET3D, développé par les chercheurs de NVIDIA, est un autre modèle puissant de génération de texte-3D qui se concentre sur la production de maillages 3D texturés de haute qualité.
Caractéristiques clés de GET3D :
a) Représentation de surface explicite : Contrairement à DreamFusion ou Shap-E, GET3D génère directement des représentations de surface explicites (maillages) sans représentations implicites intermédiaires.
b) Génération de texture : Le modèle inclut une technique de rendu différentiable pour apprendre et générer des textures de haute qualité pour les maillages 3D.
c) Architecture basée sur GAN : GET3D utilise une approche de réseau génératif adversatif (GAN), qui permet des temps d’inférence rapides une fois le modèle formé.
Avantages :
- Géométrie et textures de haute qualité
- Temps d’inférence rapides
- Intégration directe avec les moteurs de rendu 3D
Limitations :
- Nécessite des données d’entraînement 3D, qui peuvent être rares pour certaines catégories d’objets
Conclusion
La génération 3D à partir de texte AI représente un changement fondamental dans la façon dont nous créons et interagissons avec le contenu 3D. En exploitant des techniques d’apprentissage automatique avancées, ces modèles peuvent produire des actifs 3D complexes et de haute qualité à partir de descriptions textuelles simples. À mesure que la technologie continue d’évoluer, nous pouvons nous attendre à voir des systèmes de texte-3D de plus en plus sophistiqués et capables qui révolutionneront des secteurs allant des jeux et du cinéma à la conception de produits et l’architecture.
J'ai passé les cinq dernières années à me plonger dans le monde fascinant de l'apprentissage automatique et de l'apprentissage profond. Ma passion et mon expertise m'ont conduit à contribuer à plus de 50 projets de génie logiciel divers, avec un accent particulier sur l'IA/ML. Ma curiosité permanente m'a également attiré vers le traitement automatique des langues, un domaine que je suis impatient d'explorer plus en détail.

You may like
-


La course aux armes de l’IA s’intensifie : le partenariat stratégique d’AMD avec OpenAI
-


OpenAI obtient un partenariat de sept ans avec AWS Cloud d’une valeur de 38 milliards de dollars
-


Optimisation des Champs de Rayonnement Neuronaux (NeRF) pour le Rendu 3D en Temps Réel sur les Plateformes de Commerce Électronique
-


Le Protocole de Contexte de Modèle de Claude (MCP) : Un Guide pour les Développeurs
-


Modèles de conception en Python pour les ingénieurs en IA et LLM : Un guide pratique
-


Microsoft AutoGen : des flux de travail d’IA multi-agents avec une automatisation avancée







