Intelligence Artificielle
Intégration de code : un guide complet

Les incorporations de code constituent une manière transformatrice de représenter des extraits de code sous forme de vecteurs denses dans un espace continu. Ces intégrations capturent les relations sémantiques et fonctionnelles entre les extraits de code, permettant ainsi des applications puissantes dans la programmation assistée par l'IA. Semblables aux intégrations de mots dans le traitement du langage naturel (NLP), les intégrations de code positionnent des extraits de code similaires rapprochés dans l'espace vectoriel, permettant aux machines de comprendre et de manipuler le code plus efficacement.
Que sont les intégrations de code ?
Les intégrations de code convertissent les structures de code complexes en vecteurs numériques qui capturent la signification et la fonctionnalité du code. Contrairement aux méthodes traditionnelles qui traitent le code comme des séquences de caractères, les intégrations capturent les relations sémantiques entre les parties du code. Ceci est crucial pour diverses tâches d’ingénierie logicielle basées sur l’IA, telles que la recherche de code, la complétion, la détection de bogues, etc.
Par exemple, considérons ces deux fonctions Python :
def add_numbers(a, b):
return a + b
def sum_two_values(x, y):
result = x + y
return result
Bien que ces fonctions semblent syntaxiquement différentes, elles effectuent la même opération. Une bonne intégration de code représenterait ces deux fonctions avec des vecteurs similaires, capturant leur similitude fonctionnelle malgré leurs différences textuelles.

Incorporation de vecteurs
Comment les intégrations de code sont-elles créées ?
Il existe différentes techniques pour créer des intégrations de code. Une approche courante consiste à utiliser des réseaux de neurones pour apprendre ces représentations à partir d’un vaste ensemble de données de code. Le réseau analyse la structure du code, y compris les jetons (mots-clés, identifiants), la syntaxe (comment le code est structuré) et potentiellement les commentaires pour connaître les relations entre les différents extraits de code.
Décomposons le processus :
- Coder sous forme de séquence: Premièrement, les extraits de code sont traités comme des séquences de jetons (variables, mots-clés, opérateurs).
- Formation sur les réseaux neuronaux: Un réseau de neurones traite ces séquences et apprend à les mapper à des représentations vectorielles de taille fixe. Le réseau prend en compte des facteurs tels que la syntaxe, la sémantique et les relations entre les éléments de code.
- Capturer les similitudes: La formation vise à positionner des extraits de code similaires (avec des fonctionnalités similaires) rapprochés dans l'espace vectoriel. Cela permet d'effectuer des tâches telles que rechercher du code similaire ou comparer des fonctionnalités.
Voici un exemple Python simplifié de la manière dont vous pouvez prétraiter le code pour l'intégration :
import ast
def tokenize_code(code_string):
tree = ast.parse(code_string)
tokens = []
for node in ast.walk(tree):
if isinstance(node, ast.Name):
tokens.append(node.id)
elif isinstance(node, ast.Str):
tokens.append('STRING')
elif isinstance(node, ast.Num):
tokens.append('NUMBER')
# Add more node types as needed
return tokens
# Example usage
code = """
def greet(name):
print("Hello, " + name + "!")
"""
tokens = tokenize_code(code)
print(tokens)
# Output: ['def', 'greet', 'name', 'print', 'STRING', 'name', 'STRING']
Cette représentation tokenisée peut ensuite être introduite dans un réseau neuronal pour être intégrée.
Approches existantes pour l'intégration de code
Les méthodes existantes d’intégration de code peuvent être classées en trois catégories principales :
Méthodes basées sur des jetons
Les méthodes basées sur des jetons traitent le code comme une séquence de jetons lexicaux. Des techniques telles que Term Frequency-Inverse Document Frequency (TF-IDF) et des modèles d'apprentissage en profondeur tels que CodeBERT tombent dans cette catégorie.
Méthodes basées sur les arbres
Les méthodes basées sur les arbres analysent le code en arbres de syntaxe abstraite (AST) ou autres structures arborescentes, capturant les règles syntaxiques et sémantiques du code. Les exemples incluent des réseaux de neurones arborescents et des modèles tels que code2vec et ASTNN.
Méthodes basées sur des graphiques
Les méthodes basées sur des graphiques construisent des graphiques à partir du code, tels que des graphiques de flux de contrôle (CFG) et des graphiques de flux de données (DFG), pour représenter le comportement dynamique et les dépendances du code. GraphCodeBERT est un exemple notable.
TransformCode : un cadre pour l'intégration de code
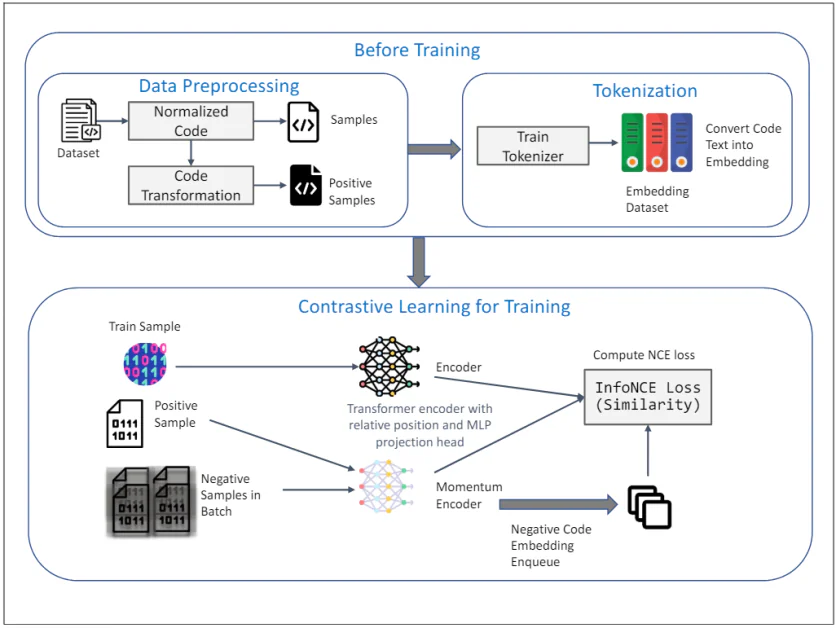
TransformCode : apprentissage non supervisé de l'intégration de code
Code de transformation est un cadre qui répond aux limites des méthodes existantes en apprenant les intégrations de code de manière contrastive. Il est indépendant du codeur et du langage, ce qui signifie qu'il peut exploiter n'importe quel modèle de codeur et gérer n'importe quel langage de programmation.
Le diagramme ci-dessus illustre le cadre de TransformCode pour l'apprentissage non supervisé de l'intégration de code à l'aide de l'apprentissage contrastif. Il se compose de deux phases principales : Avant la formation et Apprentissage contrastif pour la formationVoici une explication détaillée de chaque composant :
Avant la formation
1. Prétraitement des données :
- Base de données: L'entrée initiale est un ensemble de données contenant des extraits de code.
- Code normalisé : Les extraits de code subissent une normalisation pour supprimer les commentaires et renommer les variables dans un format standard. Cela contribue à réduire l'influence de la dénomination des variables sur le processus d'apprentissage et améliore la généralisabilité du modèle.
- Transformation des codes : Le code normalisé est ensuite transformé à l'aide de diverses transformations syntaxiques et sémantiques pour générer des échantillons positifs. Ces transformations garantissent que la signification sémantique du code reste inchangée, fournissant des échantillons diversifiés et robustes pour l'apprentissage contrastif.
2. Tokénisation :
- Tokeniseur de train : Un tokenizer est formé sur l'ensemble de données de code pour convertir le texte du code en intégrations. Cela implique de décomposer le code en unités plus petites, telles que des jetons, qui peuvent être traitées par le modèle.
- Ensemble de données intégré : Le tokenizer entraîné est utilisé pour convertir l’ensemble des données de code en intégrations, qui servent d’entrée pour la phase d’apprentissage contrastif.
Apprentissage contrastif pour la formation
3. Processus de formation :
- Échantillon de train : Un échantillon de l'ensemble de données de formation est sélectionné comme représentation du code de requête.
- Échantillon positif : L'échantillon positif correspondant est la version transformée du code de requête, obtenue lors de la phase de prétraitement des données.
- Échantillons négatifs par lots : Les échantillons négatifs sont tous les autres échantillons de code du mini-lot actuel qui sont différents de l'échantillon positif.
4. Encodeur et encodeur Momentum :
- Encodeur de transformateur avec position relative et tête de projection MLP : La requête et les échantillons positifs sont introduits dans un encodeur Transformer. L'encodeur intègre un codage de position relative pour capturer la structure syntaxique et les relations entre les jetons dans le code. Une tête de projection MLP (Multi-Layer Perceptron) est utilisée pour mapper les représentations codées sur un espace de dimension inférieure où l'objectif d'apprentissage contrastif est appliqué.
- Encodeur d'impulsion : Un encodeur de momentum est également utilisé, mis à jour par une moyenne mobile des paramètres de l'encodeur de requête. Cela permet de maintenir la cohérence et la diversité des représentations, évitant ainsi l'effondrement de la perte de contraste. Les échantillons négatifs sont codés à l'aide de cet encodeur de momentum et mis en file d'attente pour le processus d'apprentissage contrastif.
5. Objectif d'apprentissage contrastif :
- Calculer la perte d'informations (similarité) : L'espace Perte InfoNCE (Noise Contrastive Estimation) est calculé pour maximiser la similarité entre la requête et les échantillons positifs tout en minimisant la similarité entre la requête et les échantillons négatifs. Cet objectif garantit que les intégrations apprises sont discriminantes et robustes, capturant la similarité sémantique des extraits de code.
L'ensemble du framework exploite les atouts de l'apprentissage contrastif pour apprendre des intégrations de code significatives et robustes à partir de données non étiquetées. L'utilisation de transformations AST et d'un codeur d'impulsion améliore encore la qualité et l'efficacité des représentations apprises, faisant de TransformCode un outil puissant pour diverses tâches d'ingénierie logicielle.
Principales fonctionnalités de TransformCode
- Flexibilité et adaptabilité : Peut être étendu à diverses tâches en aval nécessitant une représentation de code.
- Efficacité et évolutivité : Ne nécessite pas de modèle volumineux ni de données de formation étendues, prenant en charge n'importe quel langage de programmation.
- Apprentissage non supervisé et supervisé : Peut être appliqué aux deux scénarios d’apprentissage en incorporant des étiquettes ou des objectifs spécifiques à une tâche.
- Paramètres ajustables : Le nombre de paramètres du codeur peut être ajusté en fonction des ressources informatiques disponibles.
TransformCode introduit une technique d'augmentation des données appelée transformation AST, appliquant des transformations syntaxiques et sémantiques aux extraits de code d'origine. Cela génère des échantillons diversifiés et robustes pour un apprentissage contrasté.
Applications des intégrations de code
L'intégration de code a révolutionné divers aspects du génie logiciel en transformant le code d'un format textuel en une représentation numérique utilisable par les modèles d'apprentissage automatique. Voici quelques applications clés :
Recherche de code améliorée
Traditionnellement, la recherche de code reposait sur la correspondance de mots clés, ce qui conduisait souvent à des résultats non pertinents. Les intégrations de code permettent une recherche sémantique, où les extraits de code sont classés en fonction de leur similarité de fonctionnalité, même s'ils utilisent des mots-clés différents. Cela améliore considérablement la précision et l’efficacité de la recherche de code pertinent dans de grandes bases de code.
Achèvement du code plus intelligent
Les outils de complétion de code suggèrent des extraits de code pertinents en fonction du contexte actuel. En tirant parti de l'intégration de code, ces outils peuvent fournir des suggestions plus précises et plus utiles en comprenant la signification sémantique du code en cours d'écriture. Cela se traduit par des expériences de codage plus rapides et plus productives.
Correction automatisée du code et détection des bogues
Les intégrations de code peuvent être utilisées pour identifier des modèles qui indiquent souvent des bogues ou des inefficacités dans le code. En analysant la similarité entre les extraits de code et les modèles de bogues connus, ces systèmes peuvent automatiquement suggérer des correctifs ou mettre en évidence les domaines qui pourraient nécessiter une inspection plus approfondie.
Amélioration de la synthèse du code et de la génération de documentation
Les bases de code volumineuses manquent souvent de documentation appropriée, ce qui rend difficile pour les nouveaux développeurs de comprendre leur fonctionnement. Les intégrations de code peuvent créer des résumés concis qui capturent l'essence des fonctionnalités du code. Cela améliore non seulement la maintenabilité du code, mais facilite également le transfert de connaissances au sein des équipes de développement.
Révisions de code améliorées
Les révisions de code sont cruciales pour maintenir la qualité du code. Les intégrations de code peuvent aider les réviseurs en mettant en évidence les problèmes potentiels et en suggérant des améliorations. De plus, ils peuvent faciliter les comparaisons entre différentes versions de code, rendant ainsi le processus de révision plus efficace.
Traitement du code multilingue
Le monde du développement logiciel ne se limite pas à un seul langage de programmation. Les intégrations de code sont prometteuses pour faciliter les tâches de traitement de code multilingue. En capturant les relations sémantiques entre le code écrit dans différents langages, ces techniques pourraient permettre des tâches telles que la recherche et l'analyse de code dans plusieurs langages de programmation.












