
Intelligence Artificielle
Cerebras présente la solution d'inférence d'IA la plus rapide au monde : une vitesse 20x à une fraction du coût
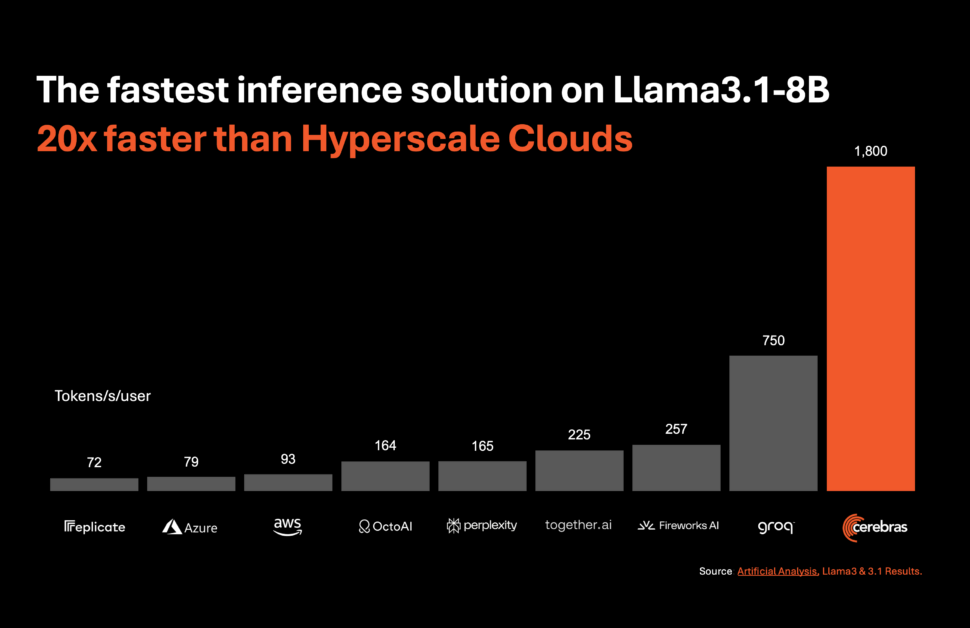
Systèmes Cerebras, pionnier du calcul de l'IA haute performance, a introduit une solution révolutionnaire qui devrait révolutionner l'inférence de l'IA. Le 27 août 2024, la société a annoncé le lancement de Cerebras Inference, le service d'inférence d'IA le plus rapide au monde. Avec des mesures de performances qui éclipsent celles des systèmes GPU traditionnels, Cerebras Inference offre une vitesse 20 fois supérieure à une fraction du coût, établissant ainsi une nouvelle référence en matière d'informatique IA.
Vitesse et rentabilité sans précédent
Cerebras Inference est conçu pour offrir des performances exceptionnelles sur divers modèles d'IA, en particulier dans le segment en évolution rapide de grands modèles de langage (LLM). Par exemple, il traite 1,800 3.1 jetons par seconde pour le modèle Llama 8 450B et 3.1 jetons par seconde pour le modèle Llama 70 20B. Ces performances sont non seulement 10 fois plus rapides que celles des solutions basées sur GPU NVIDIA, mais elles sont également proposées à un coût nettement inférieur. Cerebras propose ce service à partir de seulement 3.1 cents par million de jetons pour le modèle Llama 8 60B et 3.1 cents par million de jetons pour le modèle Llama 70 100B, ce qui représente une amélioration de XNUMX fois du rapport qualité-prix par rapport aux offres existantes basées sur GPU.
Maintenir la précision tout en repoussant les limites de la vitesse
L’un des aspects les plus impressionnants de Cerebras Inference est sa capacité à maintenir une précision de pointe tout en offrant une vitesse inégalée. Contrairement à d'autres approches qui sacrifient la précision au profit de la vitesse, la solution de Cerebras reste dans le domaine des 16 bits pendant toute la durée de l'inférence. Cela garantit que les gains de performances ne se font pas au détriment de la qualité des sorties du modèle d’IA, un facteur crucial pour les développeurs axés sur la précision.
Micah Hill-Smith, co-fondateur et PDG d'Artificial Analysis, a souligné l'importance de cette réalisation : «Cerebras offre des vitesses d'un ordre de grandeur plus rapides que les solutions basées sur GPU pour les modèles AI Llama 3.1 8B et 70B de Meta. Nous mesurons des vitesses supérieures à 1,800 3.1 jetons de sortie par seconde sur Llama 8 446B, et supérieures à 3.1 jetons de sortie par seconde sur Llama 70 XNUMXB – un nouveau record dans ces benchmarks.
L’importance croissante de l’inférence de l’IA
Inférence IA est le segment du calcul de l’IA qui connaît la croissance la plus rapide, représentant environ 40 % du marché total du matériel d’IA. L’avènement de l’inférence d’IA à haut débit, telle que celle proposée par Cerebras, s’apparente à l’introduction de l’Internet haut débit, ouvrant de nouvelles opportunités et annonçant une nouvelle ère pour les applications d’IA. Avec Cerebras Inference, les développeurs peuvent désormais créer des applications d'IA de nouvelle génération qui nécessitent des performances complexes en temps réel, telles que des agents d'IA et des systèmes intelligents.
Andrew Ng, fondateur de DeepLearning.AI, a souligné l'importance de la rapidité dans le développement de l'IA : «DeepLearning.AI dispose de plusieurs flux de travail agentiques qui nécessitent d'inviter un LLM à plusieurs reprises pour obtenir un résultat. Cerebras a construit une capacité d'inférence incroyablement rapide qui sera très utile pour de telles charges de travail. »

Large soutien industriel et partenariats stratégiques
Cerebras a obtenu un fort soutien de la part des leaders de l'industrie et a formé des partenariats stratégiques pour accélérer le développement d'applications d'IA. Kim Branson, vice-président directeur de l'IA/ML chez GlaxoSmithKline, l'un des premiers clients de Cerebras, a souligné le potentiel de transformation de cette technologie : "La vitesse et l'échelle changent tout."
D'autres sociétés, comme LiveKit, Perplexité, et Meter, ont également exprimé leur enthousiasme quant à l'impact que Cerebras Inference aura sur leurs opérations. Ces entreprises exploitent la puissance des capacités de calcul de Cerebras pour créer des expériences d'IA plus réactives et plus proches des humains, améliorer l'interaction des utilisateurs dans les moteurs de recherche et améliorer les systèmes de gestion de réseau.
Inférence Cerebras : niveaux et accessibilité
Cerebras Inference est disponible sur trois niveaux à des prix compétitifs : gratuit, développeur et entreprise. L'offre gratuite offre un accès gratuit à l'API avec des limites d'utilisation généreuses, ce qui la rend accessible à un large éventail d'utilisateurs. Le niveau Développeur offre une option de déploiement flexible et sans serveur, avec des modèles Llama 3.1 au prix de 10 cents et 60 cents par million de jetons. Le niveau Entreprise s'adresse aux organisations ayant des charges de travail soutenues, offrant des modèles affinés, des accords de niveau de service personnalisés et une assistance dédiée, avec des tarifs disponibles sur demande.
Alimenter l'inférence cérébrale : le moteur à l'échelle des plaquettes 3 (WSE-3)
Au cœur de Cerebras Inference se trouve le système Cerebras CS-3, alimenté par le Wafer Scale Engine 3 (WSE-3), leader du secteur. Ce processeur IA est inégalé en termes de taille et de vitesse, offrant 7,000 100 fois plus de bande passante mémoire que le H3 de NVIDIA. L'échelle massive du WSE-XNUMX lui permet de gérer de nombreux utilisateurs simultanés, garantissant des vitesses fulgurantes sans compromettre les performances. Cette architecture permet à Cerebras d'éviter les compromis qui affectent généralement les systèmes basés sur GPU, offrant ainsi les meilleures performances de leur catégorie pour les charges de travail d'IA.
Intégration transparente et API conviviale pour les développeurs
Cerebras Inference est conçu pour les développeurs. Il dispose d'une API entièrement compatible avec l'API OpenAI Chat Completions, permettant une migration facile avec un minimum de modifications de code. Cette approche conviviale pour les développeurs garantit que l'intégration de Cerebras Inference dans les flux de travail existants est aussi transparente que possible, permettant un déploiement rapide d'applications d'IA hautes performances.
Cerebras Systems : stimuler l'innovation dans tous les secteurs
Cerebras Systems n'est pas seulement un leader dans le domaine de l'informatique IA, mais également un acteur clé dans divers secteurs, notamment la santé, l'énergie, le gouvernement, le calcul scientifique et les services financiers. Les solutions de l'entreprise ont joué un rôle déterminant dans les percées réalisées dans des institutions telles que les National Laboratories, Aleph Alpha, la Mayo Clinic et GlaxoSmithKline.
En offrant une vitesse, une évolutivité et une précision inégalées, Cerebras permet aux organisations de ces secteurs de résoudre certains des problèmes les plus difficiles en matière d'IA et au-delà. Qu'il s'agisse d'accélérer la découverte de médicaments dans le domaine de la santé ou d'améliorer les capacités informatiques dans la recherche scientifique, Cerebras est à l'avant-garde de l'innovation.
Conclusion : une nouvelle ère pour l'inférence de l'IA
Cerebras Systems établit une nouvelle norme en matière d'inférence d'IA avec le lancement de Cerebras Inference. En offrant 20 fois la vitesse des systèmes GPU traditionnels à une fraction du coût, Cerebras rend non seulement l'IA plus accessible, mais ouvre également la voie à la prochaine génération d'applications d'IA. Grâce à sa technologie de pointe, ses partenariats stratégiques et son engagement en faveur de l'innovation, Cerebras est sur le point de conduire l'industrie de l'IA vers une nouvelle ère de performances et d'évolutivité sans précédent.
Pour plus d'informations sur Cerebras Systems et pour essayer Cerebras Inference, visitez www.cerebras.ai.







