Intelligence artificielle
Évaluation de la capture du carbone dans les arbres avec l’apprentissage automatique

De nouvelles recherches menées par IBM visent à quantifier l’étendue de la capture du carbone par les arbres et à améliorer l’environnement, en utilisant uniquement des images aériennes et des données LiDAR disponibles. La méthode vise à évaluer dans quelle mesure les initiatives de plantation d’arbres compensent les émissions de carbone, et à fournir une matrice fonctionnelle pour quantifier la valeur des programmes de plantation d’arbres qui sont de plus en plus utilisés par les entreprises et les autorités municipales pour contrebalancer les effets négatifs des infrastructures, des développements et d’autres activités productrices de carbone existants et proposés.
Pour démontrer la nouvelle méthodologie, le document – rédigé par les chercheurs d’IBM Levente Klein, Conrad Albrecht et Wang Zhou – évalue les images aériennes de l’arrondissement de Manhattan à New York, et calcule que les arbres qui habitent cette zone représentent 52 000 tonnes de carbone stocké.

Estimation de la capture de carbone pour la partie ouest de l’arrondissement de Manhattan à New York. Source : https://arxiv.org/pdf/2106.00182.pdf
Le marché émergent du carbone est actuellement servi par diverses méthodes pour estimer la compensation carbone. Les modèles divers utilisés sont difficiles à comparer, car ils ne partagent pas de métriques ou de méthodes communes. De plus, de nombreux modèles extrapolent des principes de petites zones d’étude à ce qui peut être une application trop large à d’autres zones, qui peuvent ne pas avoir les mêmes caractéristiques, ou ne pas produire la même estimation des avantages du carbone.
En outre, de nombreuses méthodes plus granulaires et moins génériques nécessitent un investissement notable dans les technologies et les calendriers de surveillance, ce qui aggrave la tentation de baser des modèles statistiques à grande échelle sur des zones d’analyse très petites, risquant ainsi des résultats imprécis ou trompeurs.
Surveillance aérienne et terrestre des arbres
Au lieu de cela, le document d’IBM propose une approche à deux volets pour identifier l’espèce et la biomasse des arbres : premièrement, des techniques d’analyse de vision par ordinateur qui peuvent dériver l’espèce d’un arbre à partir de photos aériennes ; et deuxièmement, la corrélation de ces informations avec des données LiDAR, capables d’ajouter des estimations de hauteur, de largeur et de volume aux images « plates » extraites des images aériennes.
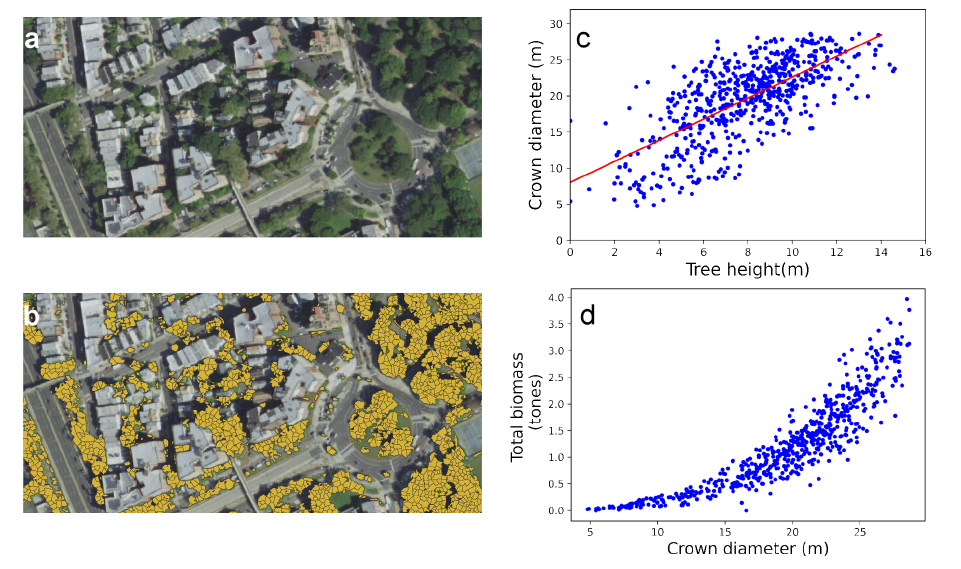
Dans le coin supérieur gauche de l’image ci-dessus, nous voyons des photos multispectrales fournies par le programme d’images agricoles nationales des États-Unis (NAIP) ; en haut à droite, des données de segmentation pour les arbres identifiés dans les images ; en bas à gauche, la relation allométrique entre le diamètre de la couronne de l’arbre et la hauteur de l’arbre établie par des données LiDAR antérieures ; et en bas à droite, la biomasse totale estimée pour la zone couverte par l’image.
L’utilisation de LiDAR pour cartographier la hauteur des arbres est répandue et peut même être mise en œuvre via une fonctionnalité native récente d’Apple dans son système d’exploitation iOS.

Utilisation de LiDAR natif dans une application pour mesurer la hauteur des arbres. Source : https://www.youtube.com/watch?v=k5DNlvq2hdE

Cartographie LiDAR des arbres. Source : https://towardsdatascience.com/applications-of-lidar-in-forestry-13686e1b15a7
Cependant, la cartographie des arbres avec LiDAR est coûteuse, donc le projet IBM a utilisé des données LiDAR acquises pour l’arrondissement de Staten pendant l’initiative de capture LiDAR de la ville de New York en 2017, ainsi que des données sur les espèces d’arbres acquises pour les cinq arrondissements dans le cadre d’un projet de données de 2015, qui a identifié 689 227 arbres dans la zone étudiée, couvrant 234 espèces d’arbres.
Évaluation de la charge de carbone des arbres de New York
La capacité de stockage de carbone estimée d’un arbre typique est d’environ 50 % de sa biomasse totale, et pour l’analyse exemplaire, le projet IBM n’a considéré que les quatre premières espèces identifiées à partir des images multispectrales NAIP.

Capacité de stockage des espèces d’arbres les plus abondantes à New York.
La régression linéaire a été utilisée pour générer un ensemble de données d’entraînement, basé sur la hauteur estimée de la canopée de l’arbre (LiDAR) et le diamètre de l’arbre (NAIP). La capacité de stockage de carbone des différentes espèces d’arbres a été prise en compte dans les calculs finals, qui montrent que les arbres de la forêt urbaine de l’arrondissement de Manhattan représentent 52 000 tonnes de carbone stocké.
Création d’un modèle de capture de carbone arborel cohérent pour l’avenir
La génération de statistiques cohérentes d’une année sur l’autre reste un problème, compte tenu du manque actuel d’un standard général pour évaluer la capacité de stockage de carbone dans les arbres. Les chercheurs proposent cette méthodologie comme un standard possible pour l’avenir, et la méthode pourrait être appliquée et affinée par des études ultérieures qui utilisent soit des données LiDAR existantes dans d’autres municipalités, soit des données collectées spécifiquement à cette fin.
Des initiatives telles que le projet de Glasgow visant à compenser les émissions de carbone en plantant 18 millions d’arbres urbains seraient plus bénéfiques pour des efforts de recherche et d’analyse statistique similaires au niveau national et international si un tel standard pouvait être établi. Il serait sans doute préférable d’avoir un standard abordable et facile à mettre en œuvre avec une large applicabilité et une précision acceptable, plutôt que la multitude de protocoles de mesure diversifiés actuels, ou l’utilisation de protocoles qui pourraient fournir des niveaux de précision plus élevés, mais qui nécessiteraient également des niveaux de financement plus importants.












